포스팅 작성 동기
이번에 동료들과 프로젝트를 하나 진행하기로 했는데, 검색 기능이 들어가야 했습니다.
관계형데이터베이스를 사용해서 where 절로 검색 결과를 반환하기에는 무리가 있다고 판단했습니다.
(이번 프로젝트에서는 검색 기능이 핵심이라고 생각했습니다....!)
따라서 검색 엔진을 도입하기로 결정했고, 그중 가장 널리쓰이는 Elasticsearch를 사용하기로 했습니다.
(많은 개발자들이 사용하기 때문에 자료를 찾는 것이 수월하다고 생각했습니다.^^)
저를 비롯하여 동료도 검색 엔진은 한번도 다뤄본적이 없기에..........🥲
동료분과 함께 Elasticsearch에 대해서 배운것을 공유할겸 + 정리할겸 포스팅을 작성하게 되었습니다...!
핵심만 콕콕 Elasticsearch 기본 개념
여기에 작성한 모든 내용은 Elastic 가이드 북를 참고하여 작성했습니다.
더 자세한 내용을 알고싶으면 해당 링크로 이동해주세요.^^

 검색 기술 기초 용어 정리
검색 기술 기초 용어 정리
검색기술을 다루다 보면 검색과 색인이라는 단어를 자주 만나게 됩니다.
특히 아파치 루씬, 그리고 Elasticsearch와 관련해서는 같은 단어가 여러 뜻으로 혼용되어 쉽게 헷갈릴 수 있으므로
혼란을 방지하기 위해 몇가지 중요한 개념의 용어들을 우선 정리하고 가도록 하겠습니다.

- 색인(indexing)
- 데이터가 검색될 수 있는 구조로 변경하기 위해 원본 문서를 검색어 토큰들로 변환하여 저장하는 과정
- 인덱스(index, indices)
- 색인 과정을 거친 결과물
- 색인된 데이터가 저장되는 저장소
- Elasticsearch 에서 Document들의 논리적인 집합을 표현하는 단위
- 검색(search)
- 인덱스에 들어있는 검색어 토큰들을 포함하고 있는 문서를 찾아가는 과정
- 질의(query)
- 사용자가 원하는 문서를 찾거나 집계 결과를 출력하기 위해 검색 시 입력하는 검색어(조건)
클러스터 구성
Elasticsearch의 시스템 구성도 입니다.
물리 서버가 존재하고 그 안에 논리적 개념으로 클러스터가 존재합니다.
클러스터는 노드로 구성되고, 각 노드에는 샤드가 존재함을 알 수 있습니다!!
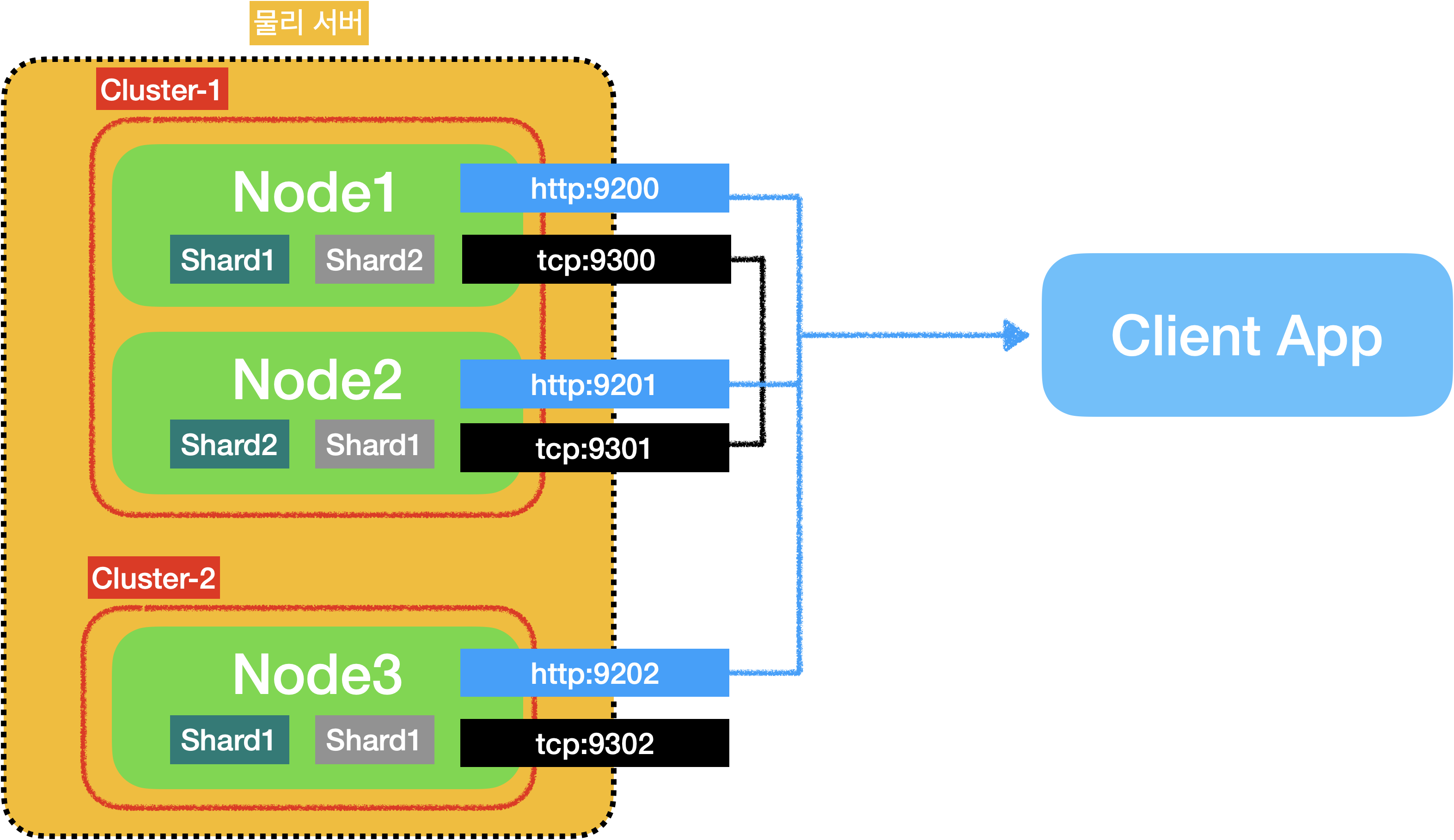

자, 이제 하나씩 살펴보자! 🔎
클러스터가 뭐지?
클러스터는 Elasticsearch에서 가장 큰 단위를 의미합니다.
(클러스터는 논리적 개념에 해당됩니다.)
Elasticsearch의 노드들은 클라이언트와 통신을 위한 http port(9200 ~ 9299),
노드 간의 데이터 교환을 위한 tcp port(9300 ~ 9399) 총 2개의 네트워크 통신을 열어두고 있습니다.
일반적으로 1개의 물리 서버마다 하나의 노드를 실행하는 것을 권장합니다.
만약, 3개의 물리 서버에서 각각 1개 씩의 노드를 실행하여 1개의 클러스터를 구축할 경우 아래와 같은 시스템 구성도를 얻을 수 있습니다.
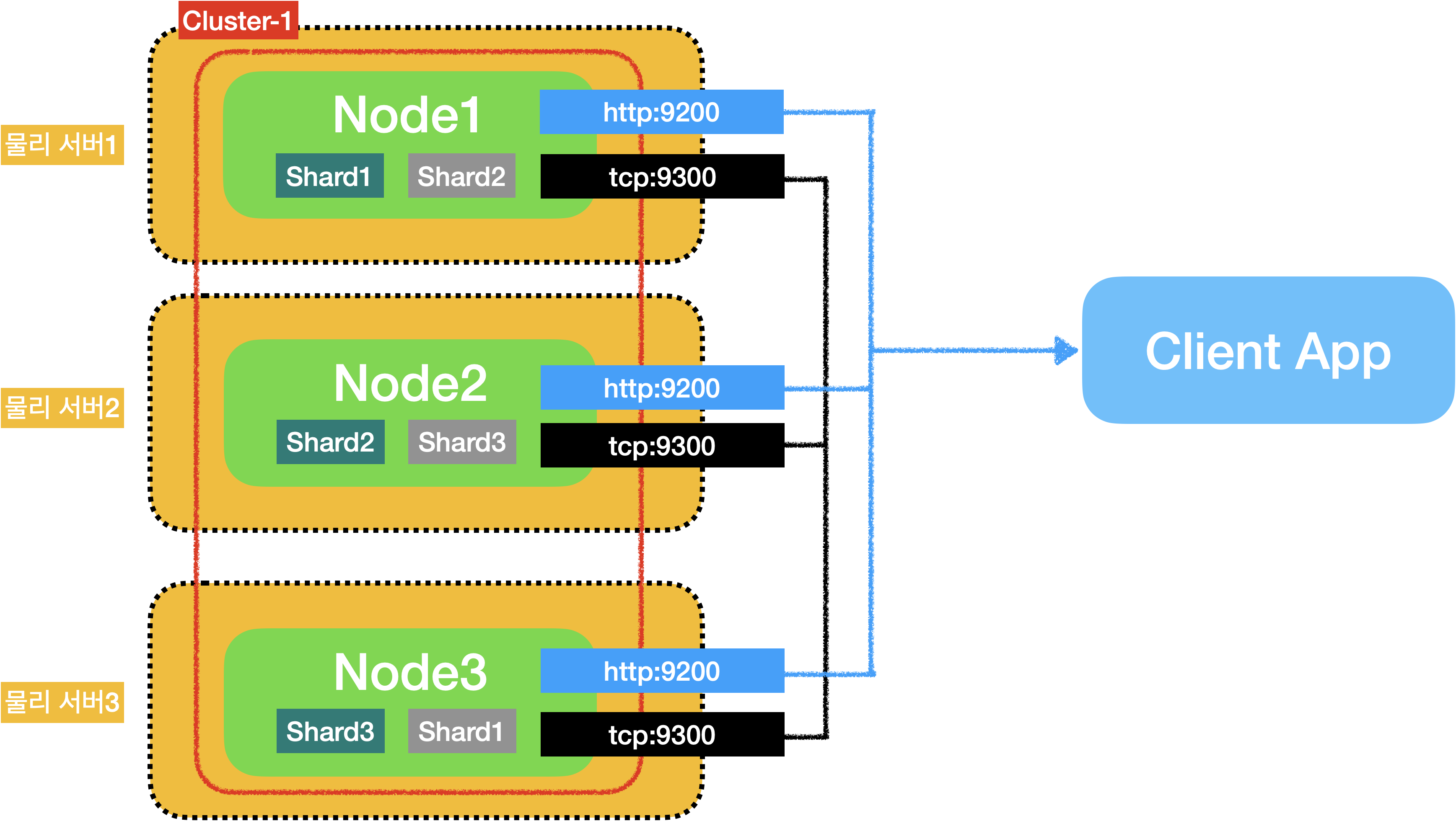

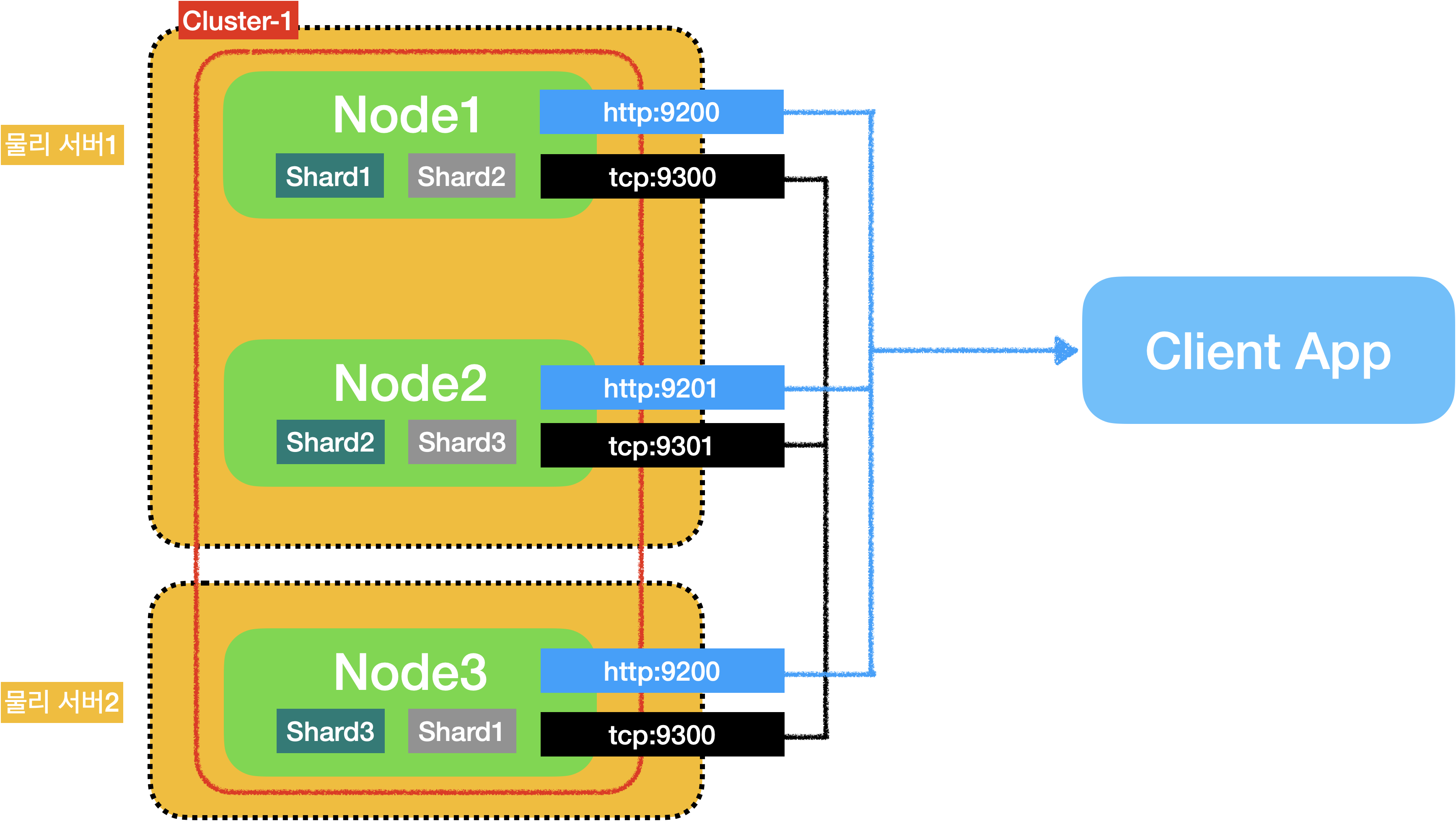
만약, 2개의 물리 서버에 서버1은 노드2개를 서버2는 노드1개를 실행하여 1개의 클러스터를 구축할 경우 아래와 같은 시스템 구성도를 얻을 수 있습니다.

클러스터는 어떻게 묶는거지?
물리적 서버와 관계없이 노드 간에 하나의 클러스터로 묶기 위해서는 클러스명(cluster.name)이 동일해야 합니다.
다시말해 노드1, 노드2, 노드3의 클러스명(cluster.name)은 모두 동일해야 한다는 의미입니다.
노드의 클러스명(cluster.name)이 다르면 물리적으로 같은 서버에 존재한다고 하더라도, 논리적으로 서로 다른 클러스터로 인식되어 실행 됩니다.
만약 1개의 물리적 서버에 노드3개를 실행시키고, 노드1과 노드2는 es-cluster-1이라는 클러스터명을 사용하고, 노드3은 es-cluster-2라는 이름을 사용할 경우 2개의 클러스터로 구축할 수 있습니다.
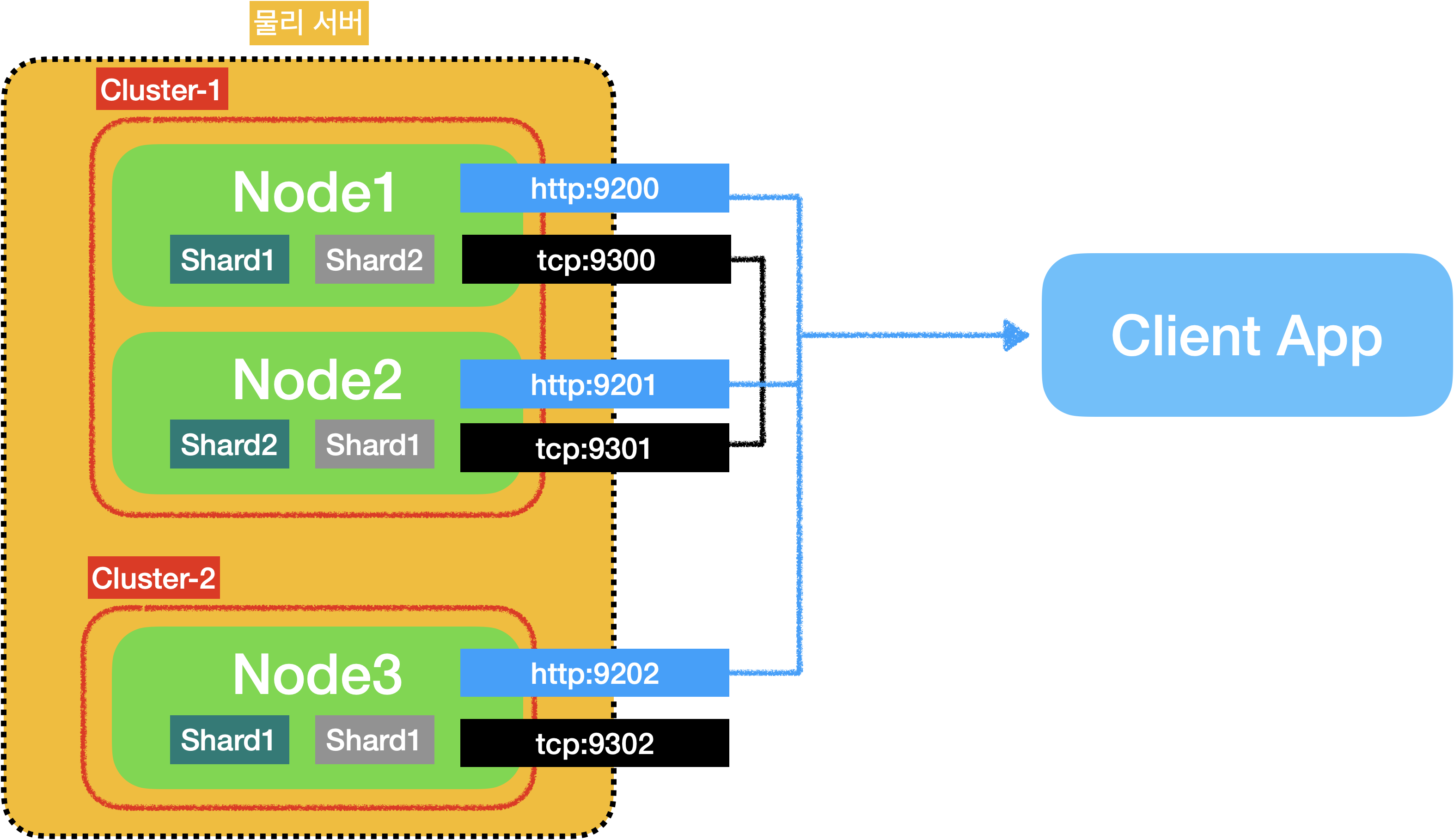

이렇게 노드에서 클러스터명을 설정한 값을 이용하여 클러스터로 바인딩하는 과정을 디스커버리 라고 합니다.
클러스터에 노드가 무수히 많아도 보통 discovery.seed_hosts 설정에는 처음에 탐색할 노드 3~5 개 정도만 설정 하면 큰 문제 없이 클러스터가 바인딩 됩니다. 보통은 마스터 후보 노드들을 지정하게 되며 처음 탐색하는 대상 노드는 반드시 먼저 가동중이어야 합니다.
클러스터와 노드 보다 더 작은 단위 인덱스와 샤드(Index & Shards)
인덱스 나온김에 용어 복습
Elasticsearch 에서는 단일 데이터 단위를 도큐먼트(document) 라고 하며 이 도큐먼트를 모아놓은 집합을 인덱스(Index) 라고 합니다.
인덱스라는 단어가 여러 뜻으로 사용되기 때문에 데이터 저장 단위인 인덱스는 인디시즈(indices) 라고 표현하기도 합니다.
이 포스팅에서는 데이터를 Elasticsearch에 저장하는 행위는 색인(Indexing), 그리고 도큐먼트의 집합 단위는 인덱스(Index) 라고 하겠습니다.
- 색인(Indexing)
- Elasticsearch에 저장하는 행위
- 도큐먼트(document)
- 단일 데이터 단위
- 인덱스(Index, indices)
- 도큐먼트(document)를 모아놓은 집합
샤드가 뭐야?
샤드는 수평적 파티션을 의미합니다.
샤드를 사용하게 되면 데이터베이스 서버 인스턴스에 분리 보관되어 로드를 분산시킵니다.
인덱스는 기본적으로 샤드라는 단위로 분리되고, 각 노드에 분산되어 저장됩니다.(샤드는 루씬의 단일 검색 인스턴스)
아래는 하나의 인덱스(도큐먼트의 집합 단위)가 5개의 샤드로 저장되도록 설정했습니다.
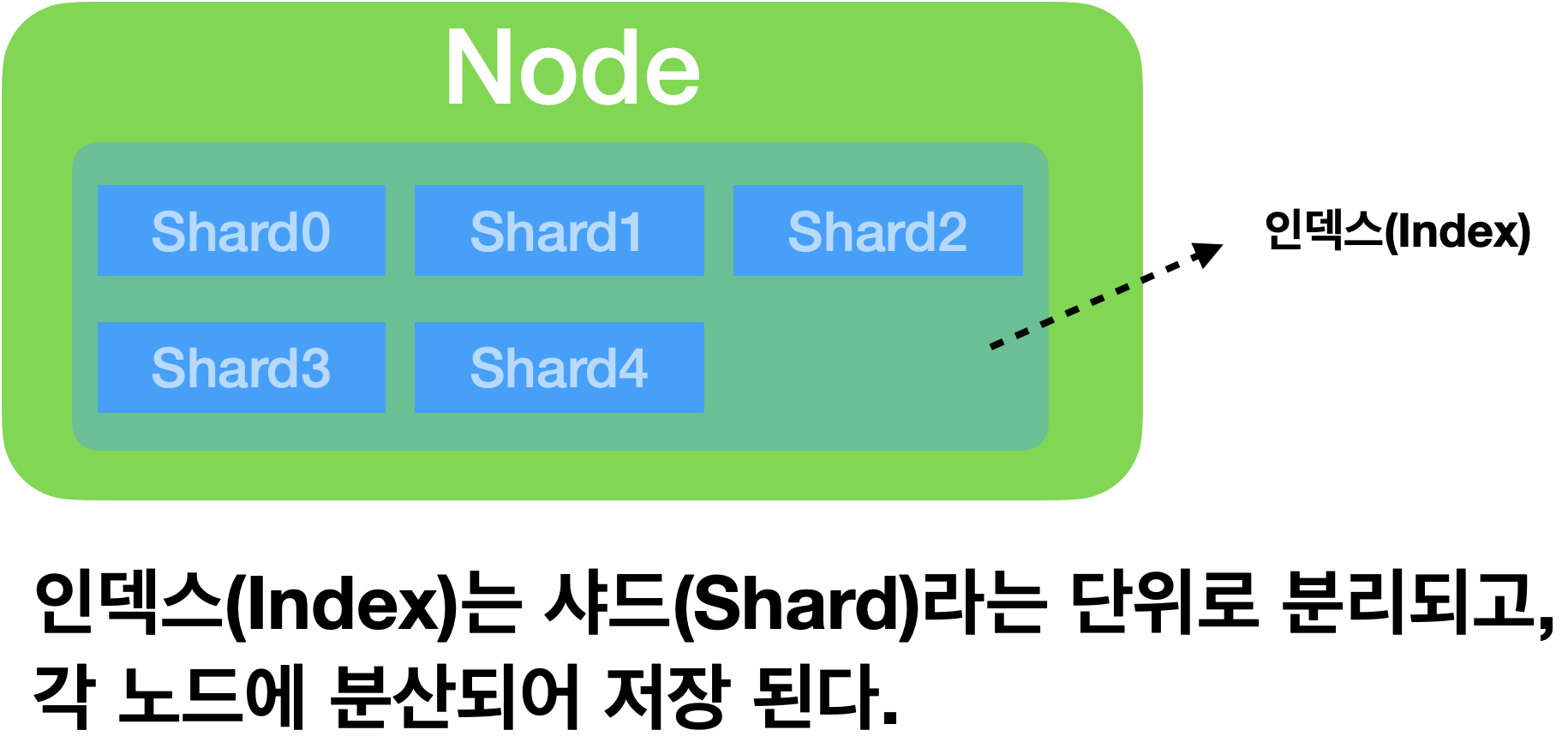

프라이머리 샤드(Primary Shard)와 복제본(Replica)
처음 생성된 샤드를 프라이머리 샤드(Primary Shard), 복제본은 리플리카(Replica) 라고 부릅니다.
예를 들어 한 인덱스가 5개의 샤드로 구성어 있고, 클러스터가 4개의 노드로 구성되어 있다고 가정하면
각각 5개의 프라이머리 샤드와 5개의 복제본, 총 10개의 샤드들이 전체 노드에 골고루 분배되어 저장됩니다.
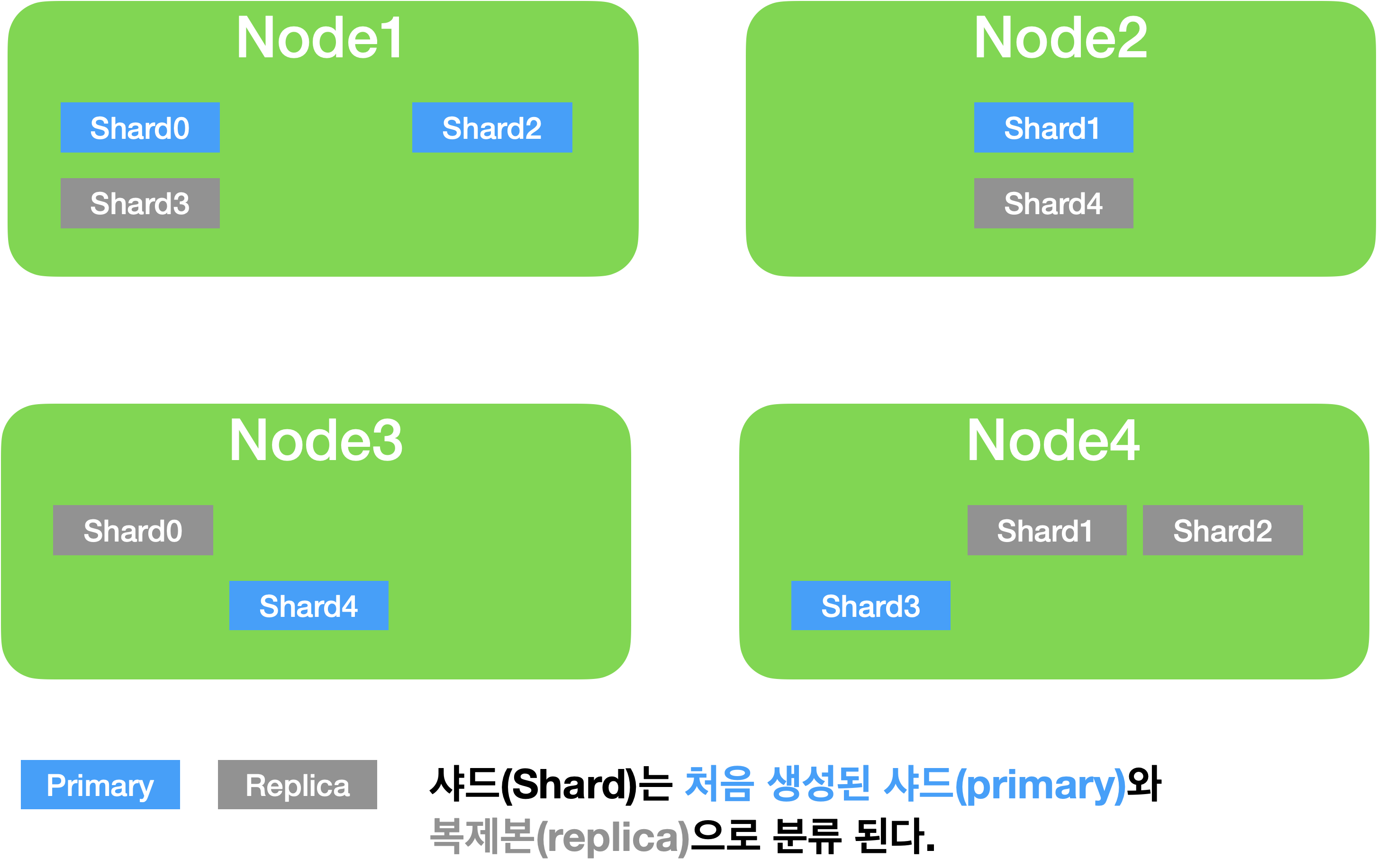

동일한 샤드를 왜 Primary와 Replica로 분리한거지?
데이터 유실을 방지하기 위해서 Primary와 Replica로 분리합니다.!
같은 샤드와 복제본은 동일한 데이터를 담고 있으며 데이터 유실을 예방하기 위해 반드시 서로 다른 노드에 저장이 되는데,
만약에 위 그림에서 Node3 노드가 시스템 다운이나 네트워크 단절등으로 사라지면 이 클러스터는 Node3 에 있던 0번과 4번 샤드들을 유실하게 됩니다.
하지만 아직 다른 노드들 Node1, Node2 에 0번, 4번 샤드가 남아있으므로 여전히 전체 데이터는 유실이 없이 사용이 가능합니다.!! 👍
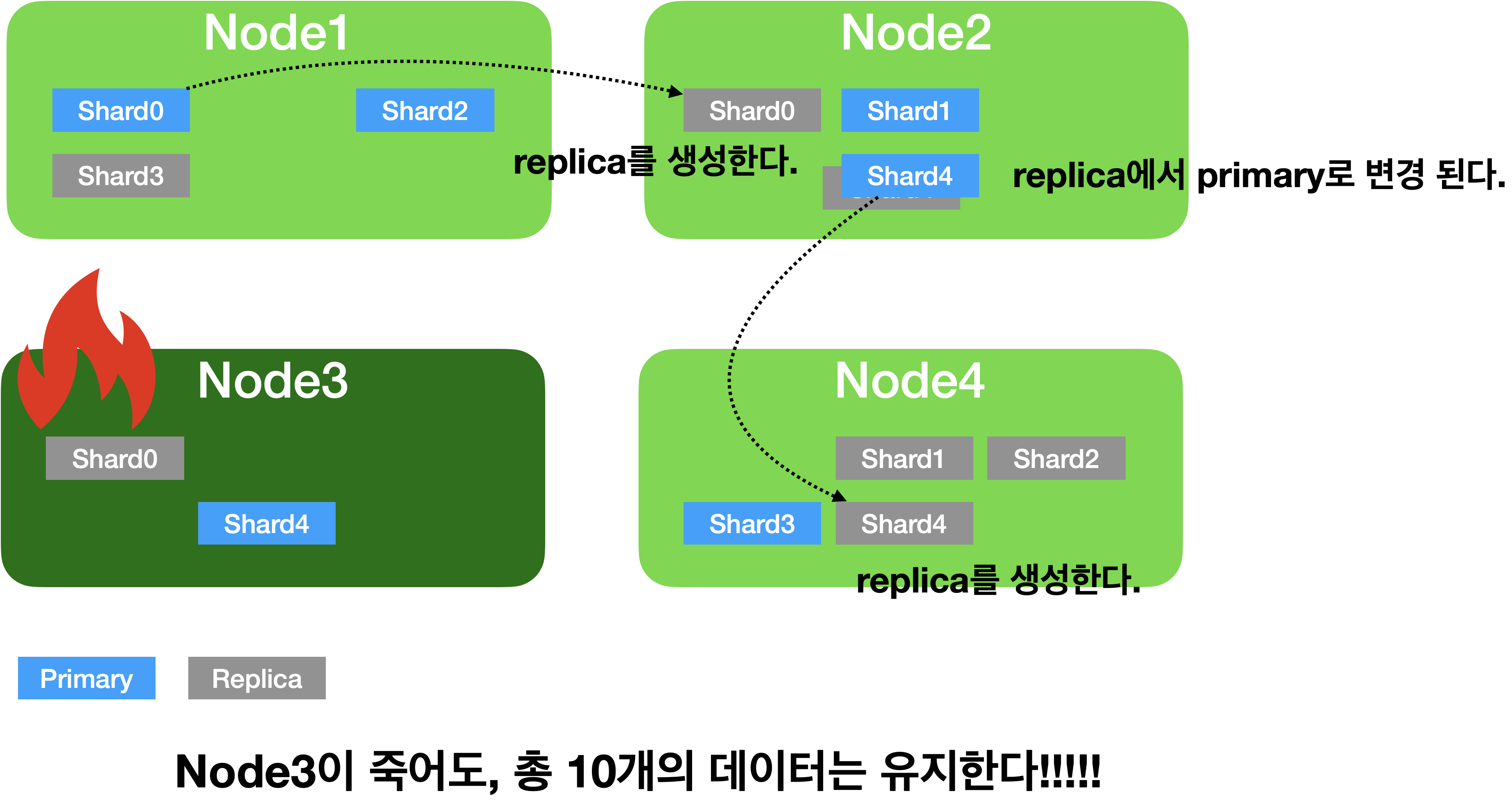

처음에 클러스터는 먼저 유실된 노드가 복구 되기를 기다립니다.
하지만 타임아웃이 지나 더 유실된 노드가 복구되지 않는다고 판단이 되면 Elasticsearch는 복제본이 사라져 1개만 남은 0번, 4번 샤드들의 복제를 시작합니다.
처음에 4개였던 노드가 3개로 줄어도 복제가 끝나면 0~4번 까지의 프라이머리 샤드, 복제본이 각각 5개씩 총 10개의 데이터로 유지됩니다. 👍
프라이머리 샤드가 유실된 경우에는 새로 프라이머리 샤드가 생성되는 것이 아니라, 남아있던 복제본이 먼저 프라이머리 샤드로 승격이 되고 다른 노드에 새로 복제본을 생성하게 됩니다.
샤드 갯수 설정
샤드의 갯수는 인덱스를 처음 생성할 때 지정할 수 있습니다.
프라이머리 샤드 수는 인덱스를 처음 생성할 때 지정하며, 인덱스를 재색인 하지 않는 이상 변경할 수 없습니다.
복제본의 갯수는 나중에 변경이 가능합니다.
중요합니다.!!!
프라이머리 샤드는 인덱스를 재색인 하지 않는 이상 변경할 수 없습니다.
복제본의 갯수는 변경할 수 있습니다.
프라이머리 샤드 설정하기
REST API를 사용할 경우 아래와 같은 방식으로 샤드를 설정할 수 있습니다.
# 프라이머리 샤드 5개, 복제본 1개인 books 인덱스 생성
$ curl -XPUT "http://localhost:9200/books" -H 'Content-Type: application/json' -d'
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}'
여기서 문제 나갑니다!
위와 같이 샤드를 설정했을 때 총 샤드는 몇개인가요?
프라이머리와 복제본 샤드를 합한 값을 알려주세요~!
정답은 10개 입니다.
프라이머리 샤드 5개, 프라이머리 샤드당 복제본 1개씩 생성되기 때문입니다.
5(프라이머리) + 5(복제본) = 10
복제본 샤드 변경하기
books 인덱스의 복제본 수를 0으로 변경하려면 아래 명령으로 업데이트가 가능합니다.
# books 인덱스의 복제본 개수를 0 으로 변경
$ curl -XPUT "http://localhost:9200/books/_settings" -H 'Content-Type: application/json' -d'
{
"number_of_replicas": 0
}'
인덱스가 2개 있으면?
만약 4개의 노드를 가진 클러스터에 프라이머리 샤드 5개, 복제본 1개인 books인덱스가 존재하고
프라이머리 샤드 3개 복제본 0개인 members인덱스가 존재하면 아래와 같은 모양으로 구성될 것 입니다.


마스터 노드와 데이터 노드(Master & Data Nodes)
순차적으로 글을 읽을 셨다면, Elasticsearch의 클러스터는 하나 이상의 노드들로 구성된다는 것을 인지하셨을 것 입니다.
이 중 하나의 노드는 마스터 노드의 역할을 수행하게 됩니다.
마스터 노드?
마스터 노드는 클러스터 상태(Cluster Status) 정보를 관리하는 노드를 의미합니다.
(인덱스의 메타 데이터, 샤드의 위치 등등…)
클러스터마다 하나의 마스터 노드가 존재하며 마스터 노드의 역할을 수행할 수 있는 노드가 없다면 클러스터는 작동이 정지됩니다.
elasticsearch.yml에 디폴트 설정은 node.master: true로 되어 있습니다.
기본적으로는 모든 노드가 마스터 노드로 선출될 수 있는 마스터 후보 노드 (master eligible node) 입니다.
만약에 현재 마스터 역할을 수행하고 있는 노드가 네트워크상에서 끊어지거나 다운되면 다른 마스터 후보 노드 중 하나가 마스터 노드로 선출이 되어 마스터 노드의 역할을 대신 수행하게 됩니다.
마스터 후보 노드들은 처음부터 마스터 노드의 정보들을 공유하고 있기 때문에 즉시 마스터 역할의 수행이 가능합니다.
클러스터가 커져서 노드와 샤드의 갯수가 엄청 많아지면?
클러스터가 커져서 노드와 샤드들의 개수가 많아지게 되면
모든 노드들이 마스터 노드의 정보를 계속 공유하는 것은 부담이 될 수 있습니다. 🥲
이때는 마스터 노드의 역할을 수행 할 후보 노드들만 따로 설정해서 유지하는 것이 전체 클러스터 성능에 도움이 될 수 있습니다. 👍
마스터 노드로 사용하지 않는 노드들은 설정값을 node.master: false 로 하여 마스터 노드의 역할을 하지 않도록 합니다.
데이터 노드?
데이터 노드는 실제로 색인된 데이터를 저장하고 있는 노드입니다.
클러스터에서 마스터 노드와 데이터 노드를 분리하여 설정 할 때 마스터 후보 노드들은 node.data: false 로 설정하여 마스터 노드 역할만 하고 데이터는 저장하지 않도록 할 수 있습니다.
마스터 노드, 데이터 노드 예제
4개의 노드를 실행하는데 node1 은 마스터의 역할만 실행하는 전용 노드이고 node2, node3, node4 는 마스터 역할은 하지 않고 데이터 저장만 하는 노드로 설정해보자.!!!
(이렇게 설정한 node1을 영어로는 Dedicated Master Node 라고 부릅니다.)
Node1(master | Dedicated Master Node)
# config/elasticsearch.yml
node.master: true # 마스터 설정
node.data: false
Node2(data), Node3(data), Node4(data)
# config/elasticsearch.yml
node.master: false
node.data: true
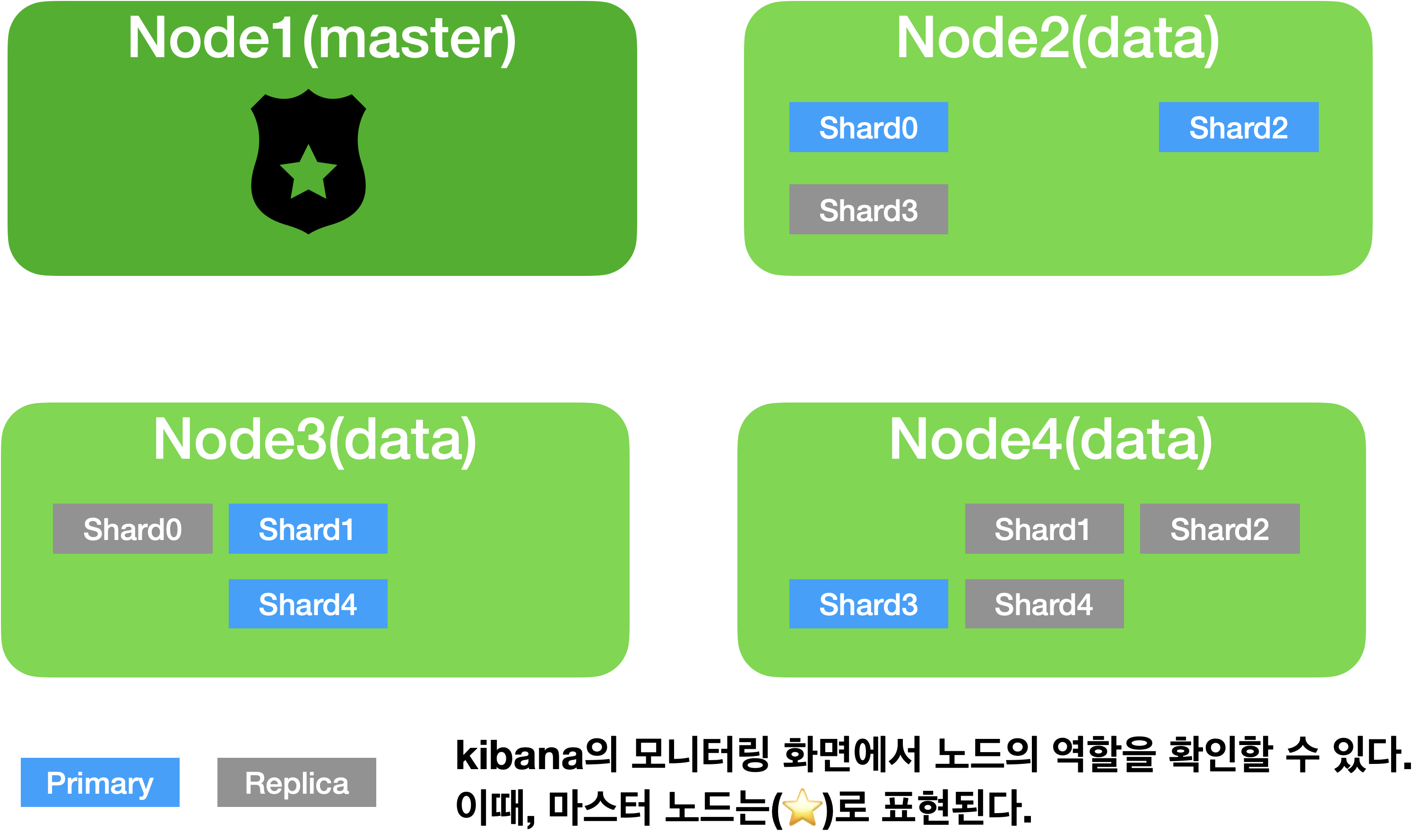
단, 실제 운영환경에서는 위 예제처럼 마스터 후보 노드는 1개만 설정하면 안되고, 최소 3개 이상의 홀수개로 설정해야합니다.
그렇게 하지 않으면 Split Brain 문제가 발생하기 때문입니다!
Split Brain 🧠
마스터 후보 노드를 하나만 설정하면 그 마스터 노드가 유실되었을 때 클러스터 전체가 작동을 정지 할 수 있습니다.
따라서 최소한의 백업용 마스터 노드를 설정하게 되는데, 이 때 마스터 후보 노드들은 3개 이상의 홀수 개를 놓는 것을 권장하고 있습니다.
만약에 마스터 후보 노드를 2개 혹은 짝수로 운영하는 경우 네트워크 유실로 인해 다음과 같은 상황을 겪을 수 있습니다. 🥲
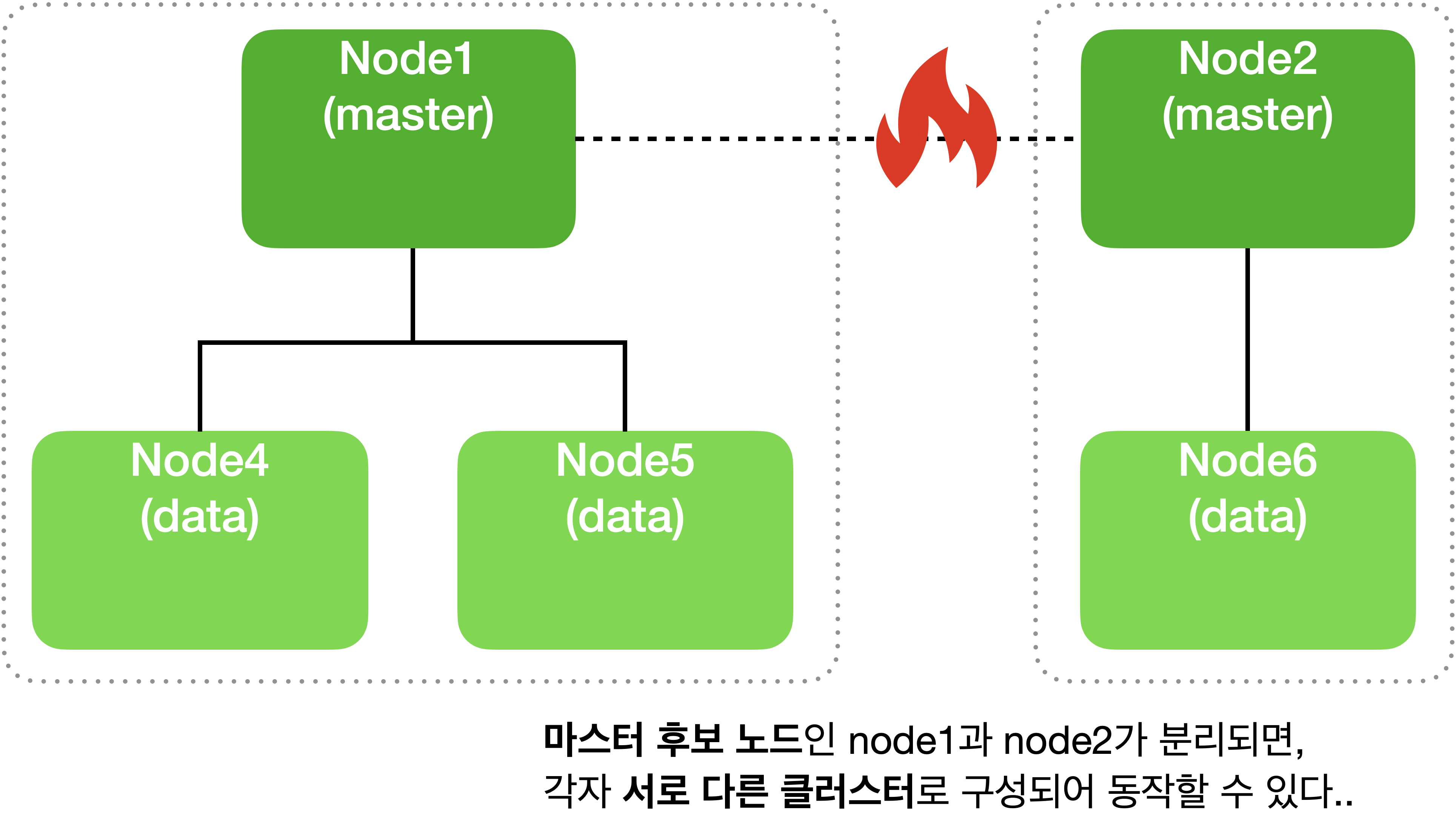

위와 같이 네트워크 단절로 마스터 후보 노드인 node-1 과 node-2 가 분리되면 각자가 서로 다른 클러스터로 구성되어 계속 동작하는 경우가 있을 수 있습니다…..
이 상태에서 각자의 클러스터에 데이터가 추가되거나 변경되고 나면 나중에 네트워크가 복구 되고 하나의 클러스터로 다시 합쳐졌을 때 데이터 정합성에 문제가 생기고 데이터 무결성이 유지될 수 없게 됩니다.
이런 문제를 Split Brain 이라고 합니다.
7.0 부터는 사용자가 최초 마스터 후보로 선출할 cluster.initial_master_nodes: [ ] 값만 설정하면 됩니다.
(node.master: true 인 노드가 추가되면 클러스터가 스스로 minimum_master_nodes 노드 값을 변경하도록 되었습니다.)
위 설정을 하고 나면 네트워크가 단절 되었을 때 minimum_master_nodes 가 2 이상인 클러스터만 살아있고 그렇지 않은 클러스터는 동작을 멈추게 됩니다.
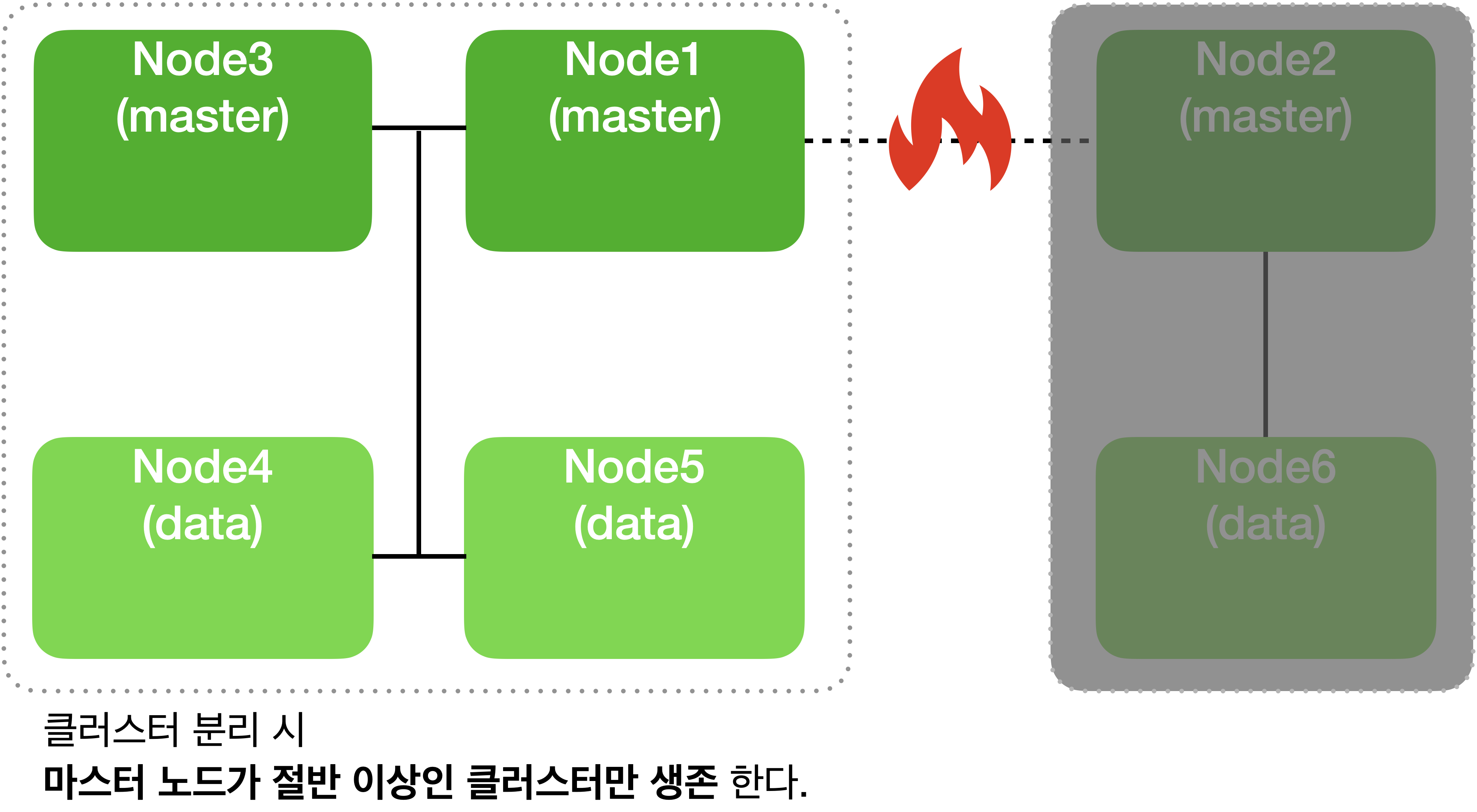

Split Brain 문제를 피하기 위해서 마스터 후보 노드 개수는 항상 홀수로 하고
가동을 위한 최소 마스터 후보 노드 설정은 (전체 마스터 후보 노드)/2+1 로 설정해야 합니다.
노드(master, data, ingest, ml)
Elasticsearch의 노드는 수행하는 다양한 역할들이 있는데, 각자의 노드들이 서로 다른 역할들을 수행하도록 클러스터를 구성할 수 있습니다.- 아래의 설정들의 모든
default value는 true이며 기본적으로 노드는 명시된 모든 역할들을 수행합니다. - 특정 값들을 false로 설정함으로서 노드의 역할들을 구분지어 클러스터를 구성할 수 있다.
node.master: true
- 마스터 후보(master eligible)노드 여부를 설정
- false인 경우 해당 노드는 마스터 노드로 선출이 불가능
- 모든 클러스터는 1개의 마스터 노드가 존재
- 마스터 노드가 다운되거나 끊어진 경우 남은 마스터 후보 노드들 중에서 새로운 마스터 노드가 선출
node.data: true
- 노드가 데이터를 저장하도록 설정
- false인 경우 데이터를 저장하지 않음
node.ingest: true
- 데이터 색인시 전처리 작업인 ingest pipeline 작업의 수행 여부를 설정
- 데이터 색인: 데이터가 검색될 수 있는 구조로 변경하는 과정
- false인 경우 해당 노드는 ingest pipeline 작업의 실행 불가능
node.ml: true
- 노드가 머신러닝 작업 수행을 할 수 있는지 여부를 지정
- false인 경우 머신러닝 작업 수행 불가
node 설정 example
- 오직 클러스터 상태를 관리하는 마스터 노드
# config/elasticsearch.yml -전용 마스터 노드 설정
path:
data: /var/lib/elasticsearch
logs: /var/log/elasticsearch
node:
master: true # 마스터 후보로 설정
data: false # 데이터를 저장하지 않음
ingest: false # 데이터 색인 불가
ml: false # 머신러닝 작업 수행 불가
- 오직 클라이언트와 통신만 하는 역할로 사용이 가능(coordinate only node)
# config/elasticsearch.yml -전용 마스터 노드 설정
node:
master: false # 마스터 후보 불가
data: false # 데이터를 저장하지 않음
ingest: false # 데이터 색인 불가
ml: false # 머신러닝 작업 수행 불가
노드 확장
- 복원력을 위해서 홀수개의 노드를 사용해라
- 클러스터 내 여러 노드간에 어플리케이션 요청을 라운드로빈해라.
- 초기 트래픽으로 로드가 분산
- 레플리카가 많을 수록 읽기 용량 증가
- 애플리케이션에서 읽기 용량을 늘리려고 클러스터에 레플리카를 나중에 추가할 수 있음
- 프라이머리 샤드가 많을 수록 쓰기 용량 제한
- 클러스터내 프라이머리 샤드의 수를 나중에 변경할 수 없음
총 샤드는 몇개인가?
PUT /testindex
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
정답은 6개이다.
프라이머리 샤드 3개와 각 프라이머리당 레플리카 1개씩
참고
'데이터베이스 > 0 + Elasticsearch' 카테고리의 다른 글
| [Elasticsearch] Elasticsearch 검색 심화 풀 텍스트 쿼리(Full Text Query) (0) | 2023.12.28 |
|---|---|
| [Elasticsearch] 초간단 REST API를 사용한 Elasticsearch CRUD (1) | 2023.12.28 |
| [Elasticsearch] 초간단 REST API를 사용한 Elasticsearch CRUD (0) | 2023.12.13 |
| [Elasticsearch] ✂️ 10분 컽 초간단 Elasticsearch + kibana 설치 매뉴얼 (0) | 2023.12.13 |