Elasticsearch의 진가 검색 기능 사용해보기(+벌크 API)
여기에 작성한 모든 내용은 Elastic 가이드 북를 참고하여 작성했습니다.
더 자세한 내용을 알고싶으면 해당 링크로 이동해주세요.^^


벌크 API(_bulk API)
검색 기능을 사용하기 위해서는 데이터가 있어야겠죠?
이전 시간에 우리는 PUT 메소드를 이용하여 인덱스와 도큐먼트를 생성하는 방법을 배웠습니다.
그런데 이렇게 요청 1개당 1개의 도큐먼트를 생성하는 것은 불편합니다.
여러 명령을 한번에 수행할 수는 없을까? 🤔
여러 명령을 배치로 수행하기 위해서 _bulk API의 사용하면 됩니다!_bulk API로 index, create, update, delete의 동작이 가능하며 delete를 제외하고는 명령문과 데이터문을 한 줄씩 순서대로 입해야 합니다.(delete는 내용 입력이 필요 없기 때문 입니다.^^)
벌크 API 실습
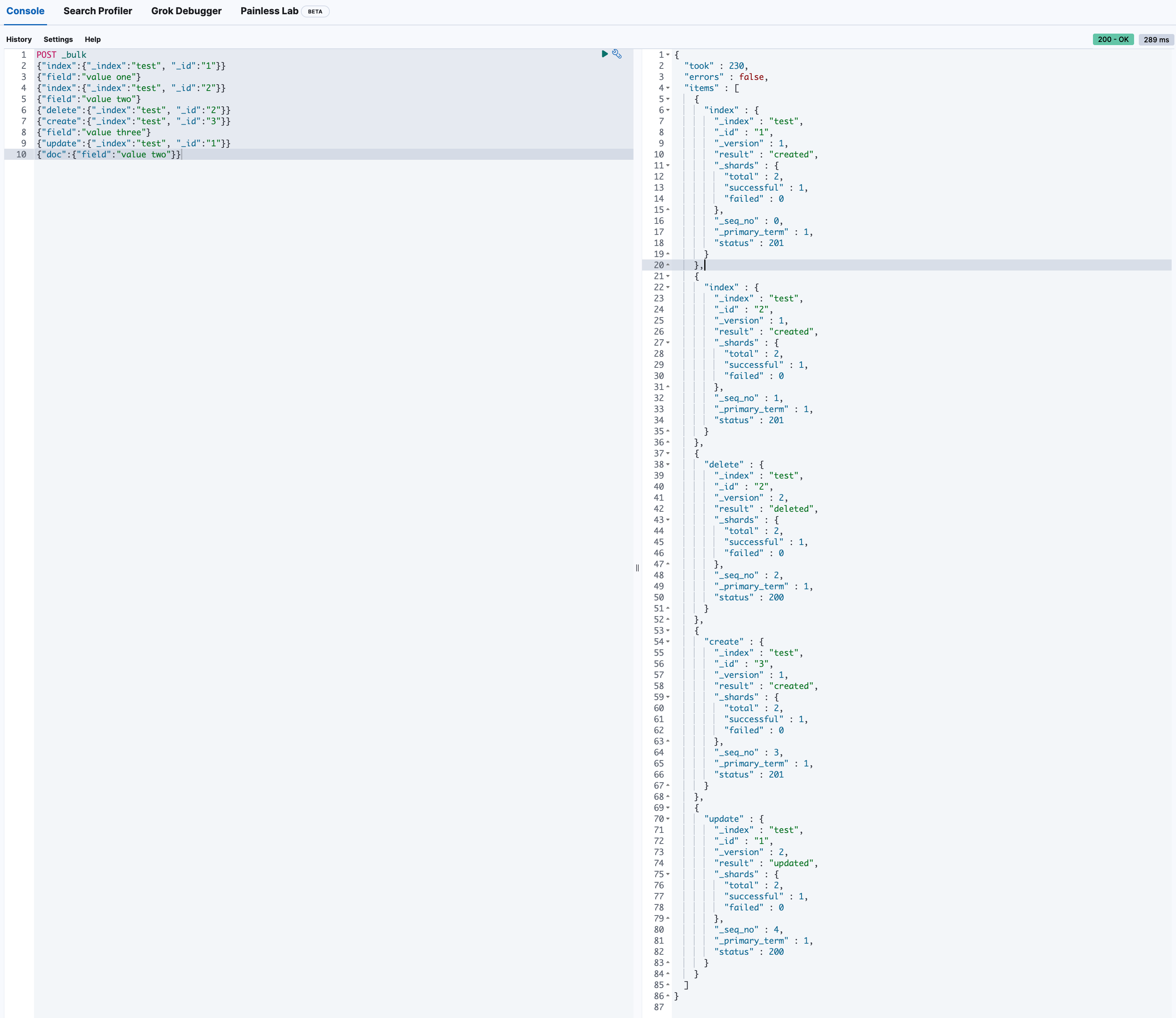
주의_bulk 의 명령문과 데이터문은 반드시 한 줄 안에 입력이 되어야 하며 줄바꿈을 허용하지 않습니다.



Request
POST _bulk
{"index":{"_index":"test", "_id":"1"}}
{"field":"value one"}
{"index":{"_index":"test", "_id":"2"}}
{"field":"value two"}
{"delete":{"_index":"test", "_id":"2"}}
{"create":{"_index":"test", "_id":"3"}}
{"field":"value three"}
{"update":{"_index":"test", "_id":"1"}}
{"doc":{"field":"value two"}}
Response
요청을 알맞게 수행했다는 응답을 확인할 수 있습니다.
{
"took" : 230,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "test",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "test",
"_id" : "2",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"delete" : {
"_index" : "test",
"_id" : "2",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 200
}
},
{
"create" : {
"_index" : "test",
"_id" : "3",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1,
"status" : 201
}
},
{
"update" : {
"_index" : "test",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1,
"status" : 200
}
}
]
}
벌크 동작은 따로따로 수행하는 것 보다 속도가 훨씬 빠릅니다.
특히 대량의 데이터를 입력 할 때는 반드시 _bulk API를 사용해야 불필요한 오버헤드가 없습니다!!
Logstash 와 Beats 그리고 Elastic 웹페이지에서 제공하는 대부분의 언어별 클라이언트에서는 데이터를 입력할 때 _bulk를 사용하도록 개발되어 있습니다.^^
_bulk 작업 중 연결이 끊어지거나 시스템이 다운되는 등의 이유로 동작이 중단 된 경우에는? 🤷♀️
아쉽게도 Elasticsearch 에는 커밋이나 롤백 등의 트랜잭션 개념이 없습니다.
따라서 _bulk 작업 중 연결이 끊어지거나 시스템이 다운되는 등의 이유로 동작이 중단 된 경우에는
어느 동작까지 실행되었는지 확인이 불가능합니다. 🥲
보통 이런 경우 전체 인덱스를 삭제하고 처음부터 다시 하는 것이 안전합니다. 👍
.json 파일 사용하기
벌크 명령을 파일로 저장하고 curl 명령으로 실행시킬 수 있습니다.
저장한 명령 파일을 --data-binary 로 지정하면 저장된 파일로 부터 입력할 명령과 데이터를 읽어올 수 있습니다.
bulk.json
{"index":{"_index":"test","_id":"1"}}
{"field":"value one"}
{"index":{"_index":"test","_id":"2"}}
{"field":"value two"}
{"delete":{"_index":"test","_id":"2"}}
{"create":{"_index":"test","_id":"3"}}
{"field":"value three"}
{"update":{"_index":"test","_id":"1"}}
{"doc":{"field":"value two"}}
shell
$ curl -XPOST "http://localhost:9200/_bulk" -H 'Content-Type: application/json' --data-binary @bulk.json
검색에 사용할 데이터 삽입하기
Request
PUT /members/_bulk
{"create": {"_index": :"members", "_id":1}}
{"id": 1, "name": "Seaung Jang", "age": 20, "skills": ["Java", "JUnit", "Spring Boot", "Spring Security"], "teamName": "dreamyPatisiel"}
{"create": {"_index": :"members", "_id":2}}
{"id": 1, "name": "Soyoung Yu", "age": 25, "skills": ["Java", "JUnit", "Spring Boot", "Spring Data JPA", "Spring MVC"], "teamName": "dreamyPatisiel"}
{"create": {"_index": :"members", "_id":3}}
{"id": 3, "name": "Minyoung Kim", "age": 29, "skills": ["Javascript", "React", "Redux"], "teamName": "dreamyPatisiel"}
{"create": {"_index": :"members", "_id":4}}
{"id": 4, "name": "Imha Lee", "age": 23, "skills": ["Framer", "Figma", "Adobe Photoshop", "Adobe Illustrator"], "teamName": "dreamyPatisiel"}
Response
{
"took" : 266,
"errors" : false,
"items" : [
{
"create" : {
"_index" : "members",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"create" : {
"_index" : "members",
"_id" : "2",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"create" : {
"_index" : "members",
"_id" : "3",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
},
{
"create" : {
"_index" : "members",
"_id" : "4",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1,
"status" : 201
}
}
]
}
검색 API(_search API)
Elasticsearch의 진가는 쿼리를 통한 검색 기능에 있습니다. !!!
검색은 인덱스 단위로 이루어집니다.GET <인덱스명>/_search 형식으로 사용합니다.
(쿼리를 입력하지 않으면 전체 도큐먼트를 찾는 match_all 검색을 합니다.)
URI 검색
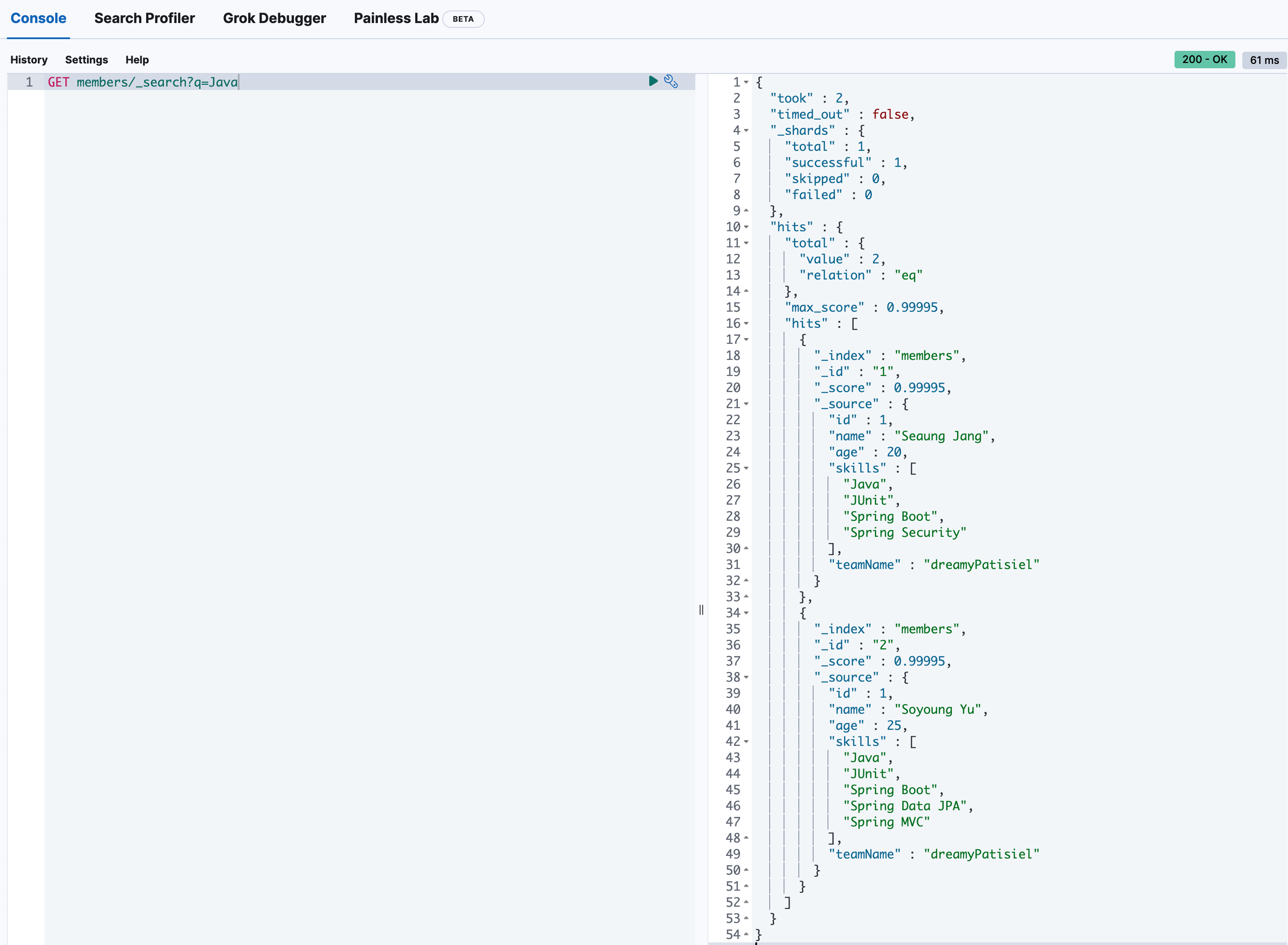
_search 뒤에 q 파라미터를 사용해서 검색어를 입력할 수 있습니다.
(이렇게 요청 주소에 검색어를 넣어 검색하는 방식을 URI 검색이라고 합니다.^^)

Request
GET members/_search?q=Java
Response
결과를 보면 hits.total.value 부분에 검색 결과 전체에 해당되는 문서의 개수가 표시되고,
다시 그 안의 hits:[ ] 구문 안에 배열로 가장 정확도가 높은 문서 10개가 나타납니다.
이 정확도를 relevancy(렐러번시 라고 읽습니다) 라고 합니다.
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.99995,
"hits" : [
{
"_index" : "members",
"_id" : "1",
"_score" : 0.99995,
"_source" : {
"id" : 1,
"name" : "Seaung Jang",
"age" : 20,
"skills" : [
"Java",
"JUnit",
"Spring Boot",
"Spring Security"
],
"teamName" : "dreamyPatisiel"
}
},
{
"_index" : "members",
"_id" : "2",
"_score" : 0.99995,
"_source" : {
"id" : 1,
"name" : "Soyoung Yu",
"age" : 25,
"skills" : [
"Java",
"JUnit",
"Spring Boot",
"Spring Data JPA",
"Spring MVC"
],
"teamName" : "dreamyPatisiel"
}
}
]
}
}
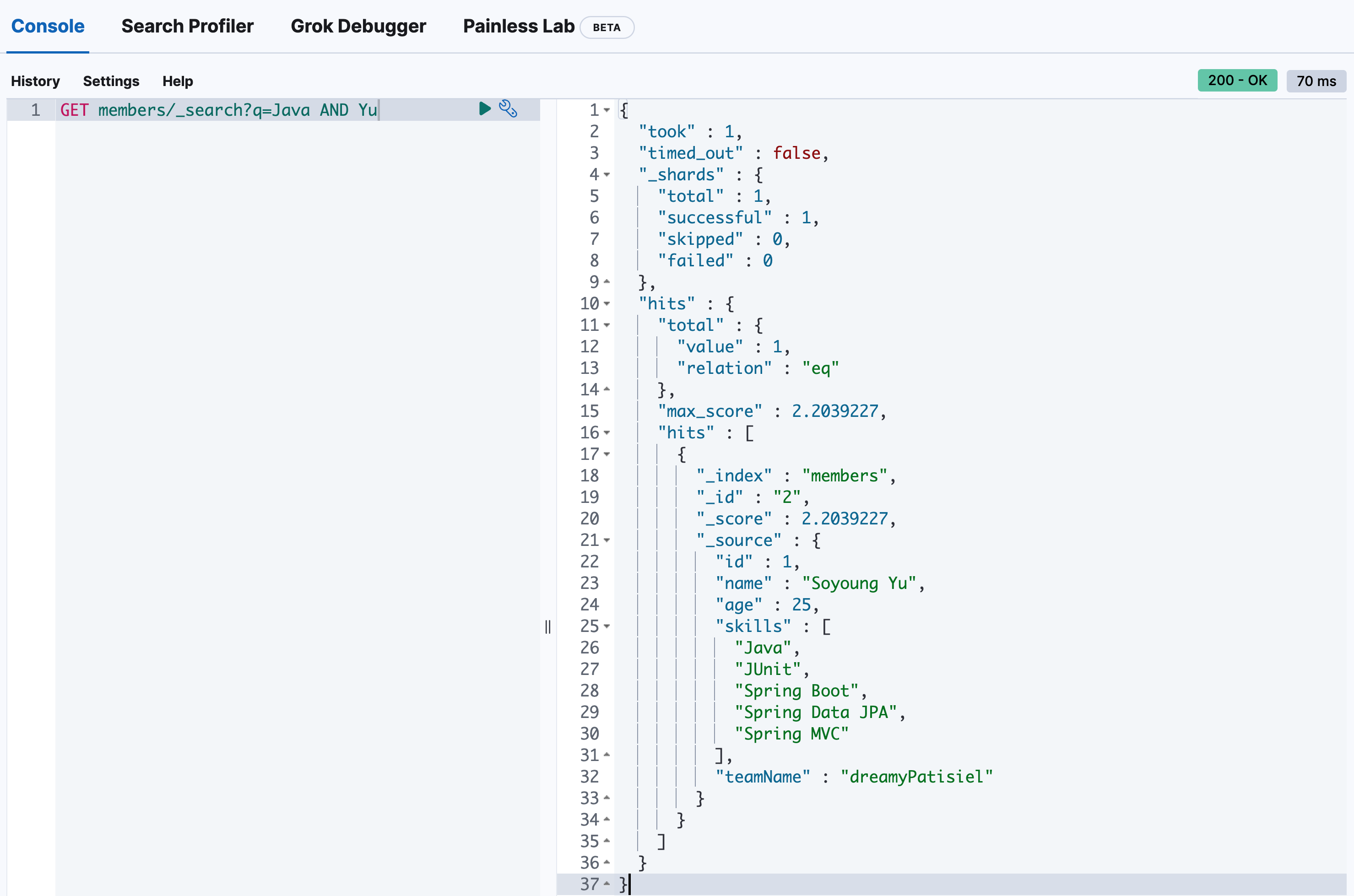
여러 검색어를 입력하고 싶은 경우?
두 개의 검색어 Java 그리고 Yu 를 AND 조건으로 검색 하려면 다음과 같이 입력하면 됩니다.
(URI 쿼리에서는 AND, OR, NOT 의 사용이 가능하며 반드시 모두 대문자로 입력해야합니다.)

Request
GET members/_search?q=Java AND Yu
ResponseJava와 Yu를 모두 포함한 members/_doc/2가 응답으로 온 것을 확인할 수 있습니다.
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 2.2039227,
"hits" : [
{
"_index" : "members",
"_id" : "2",
"_score" : 2.2039227,
"_source" : {
"id" : 1,
"name" : "Soyoung Yu",
"age" : 25,
"skills" : [
"Java",
"JUnit",
"Spring Boot",
"Spring Data JPA",
"Spring MVC"
],
"teamName" : "dreamyPatisiel"
}
}
]
}
}
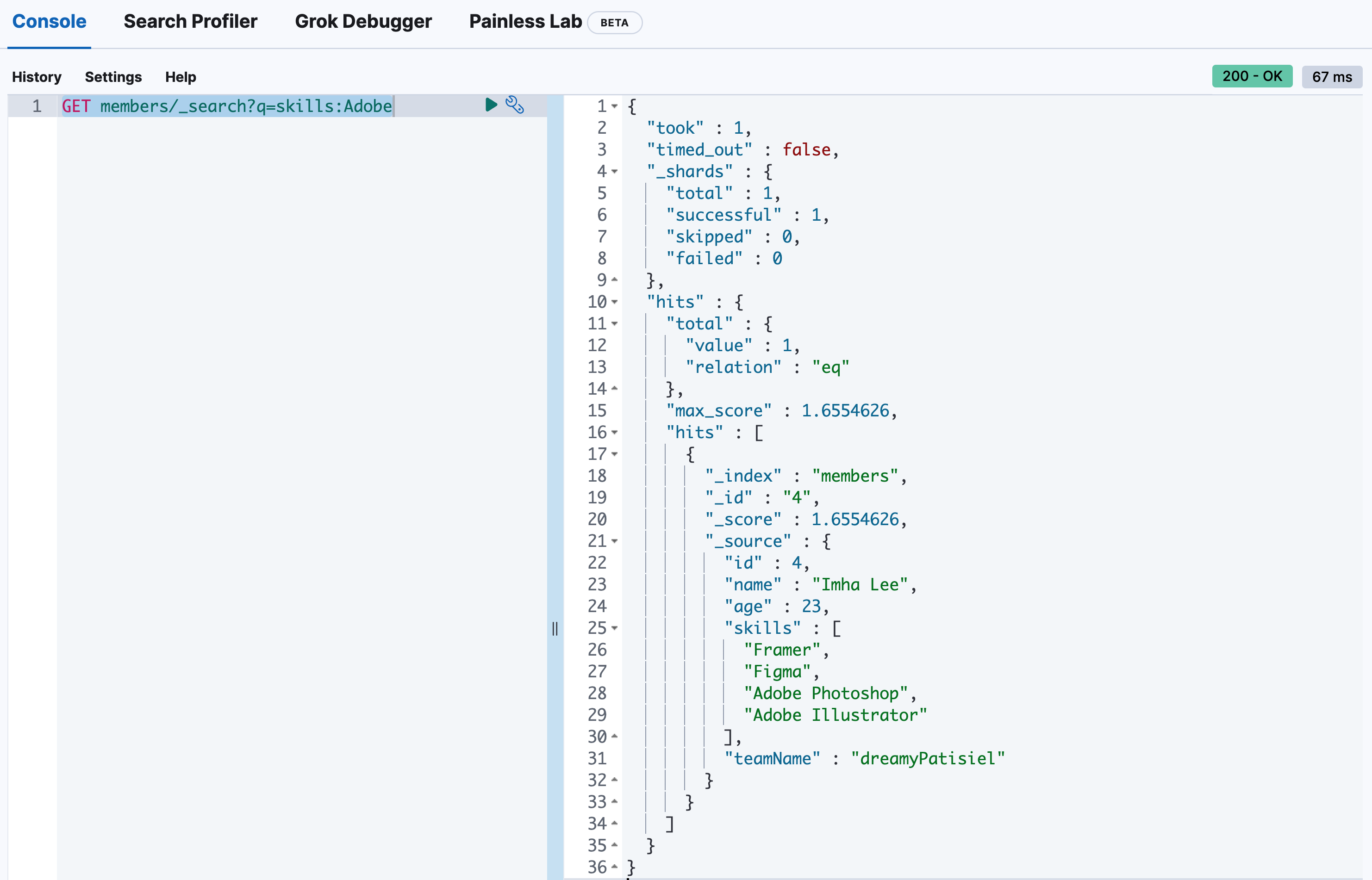
🙋 저는 특정 필드에서 검색하고 싶어요.
특정 필드에서 검색하고 싶으시면 다음과 같이 <필드명>:<검색어> 형태로 사용하면 됩니다!
(검색은 항상 필드를 지정해서 하는 것이 좋습니다. 👍)

Request
GET members/_search?q=skills:Adobe
Response
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.6554626,
"hits" : [
{
"_index" : "members",
"_id" : "4",
"_score" : 1.6554626,
"_source" : {
"id" : 4,
"name" : "Imha Lee",
"age" : 23,
"skills" : [
"Framer",
"Figma",
"Adobe Photoshop",
"Adobe Illustrator"
],
"teamName" : "dreamyPatisiel"
}
}
]
}
}
데이터 본문(data body) 검색
Elasticsearch에서는 좀 더 복잡한 검색을 위해서는 데이터 본문(data body) 검색을 이용합니다.
Elasticsearch의 QueryDSL을 사용하며 쿼리 또한 Json 형식으로 되어 있습니다.
그중 가장 쉽고 많이 사용되는 것은 match 쿼리 예시를 먼저 보여드리겠습니다.!!!
여기서는 간단하게 “아! 복잡한 검색을 위해 데이터 본문 검색방식을 사용하는 구나!” 정도만 생각하면 될 것 같습니다^^~!
Request
쿼리 입력은 항상 query 지정자로 시작합니다.
그 다음 레벨에서 쿼리의 종류를 지정하는데 위에서는 match 쿼리를 지정했습니다.
GET members/_search
{
"query": {
"match": {
"skills": "React"
}
}
}
Response
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.513566,
"hits" : [
{
"_index" : "members",
"_id" : "3",
"_score" : 1.513566,
"_source" : {
"id" : 3,
"name" : "Minyoung Kim",
"age" : 29,
"skills" : [
"Javascript",
"React",
"Redux"
],
"teamName" : "dreamyPatisiel"
}
}
]
}
}
고생하셨습니다.^^
참고
'데이터베이스 > 0 + Elasticsearch' 카테고리의 다른 글
| [Elasticsearch] Elasticsearch 검색 심화 풀 텍스트 쿼리(Full Text Query) (0) | 2023.12.28 |
|---|---|
| [Elasticsearch] 초간단 REST API를 사용한 Elasticsearch CRUD (0) | 2023.12.13 |
| [Elasticsearch] ✂️ 10분 컽 초간단 Elasticsearch + kibana 설치 매뉴얼 (0) | 2023.12.13 |
| [Elasticsearch] 핵심만 콕콕 Elasticsearch 기본 개념 (0) | 2023.12.07 |