지난 시간 선형모델에 대해서 알아보았다.
이번에는 비선형모델에 대해서 알아보자~
자 드가자~~~~~~~~~~~~~~~~~~
비선형모델

실제 세계는 위와 같이 선형이 아니고 노이즈가 섞이게 된다.
이러한 문제를 해결하기 위해 비선형 모델이 필요하다.
과소적합과 과잉적합(OverFitting and UnderFitting)
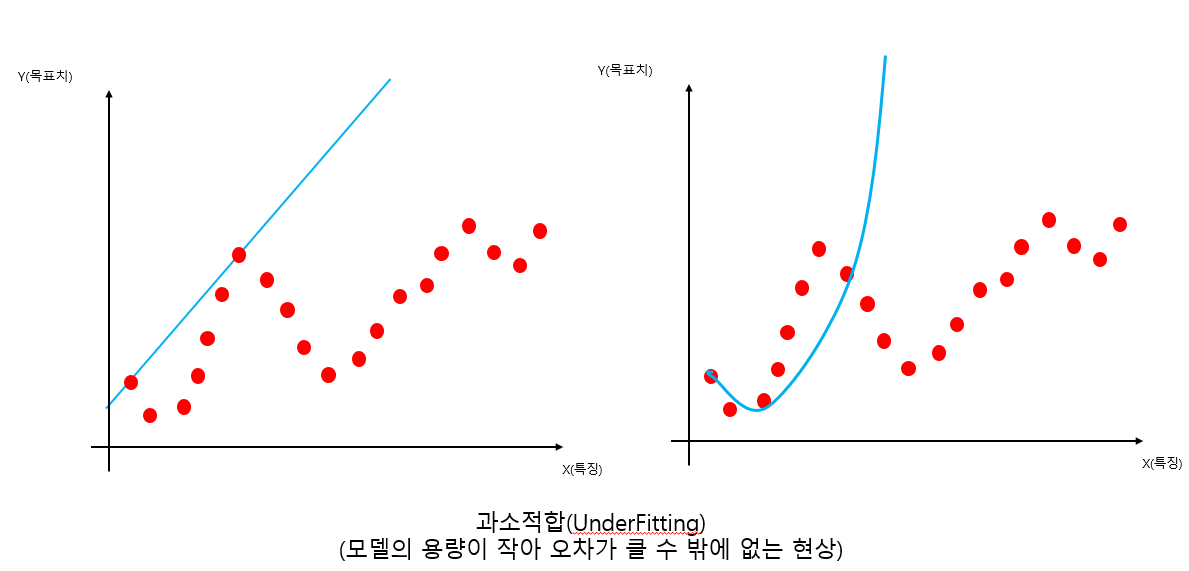

과잉적합시 부정한 예측이 발생한다.
-> 훈련집합에 대한 오차는 감소하지만 새로운(new)데이터 예측 시 오차가 증가
--> 다시말해서, 일반화 능력이 저하
Question : 어떻게 하면 과잉적합 문제를 해결할 수 있을까?
문제를 해결하기 위해서는 먼저 바이어스와 분산의 의미를 알아야한다.
바이어스와 분산
훈련집합을 여러 번 수집하여 1차 ~ n차방정식에 적용하는 실험
바이어스 : 훈련집합을 여러번 서로 다르게 수집 후 모델에 적용하고 예측치 확인시 그 예측치가 이루는 오차의 평균을 의미한다.
즉, 바이어스가 작을 수록 오차가 적다는 의미이다.
1차 모델은 바이어스가 크지만 낮은 분산을 갖고 있다.
9차 모델은 바이어스가 작지만 높은 분산을 갖고 있다.(훈련데이터가 조금만 바껴도 예측치의 값이 크게 변하기 때문)
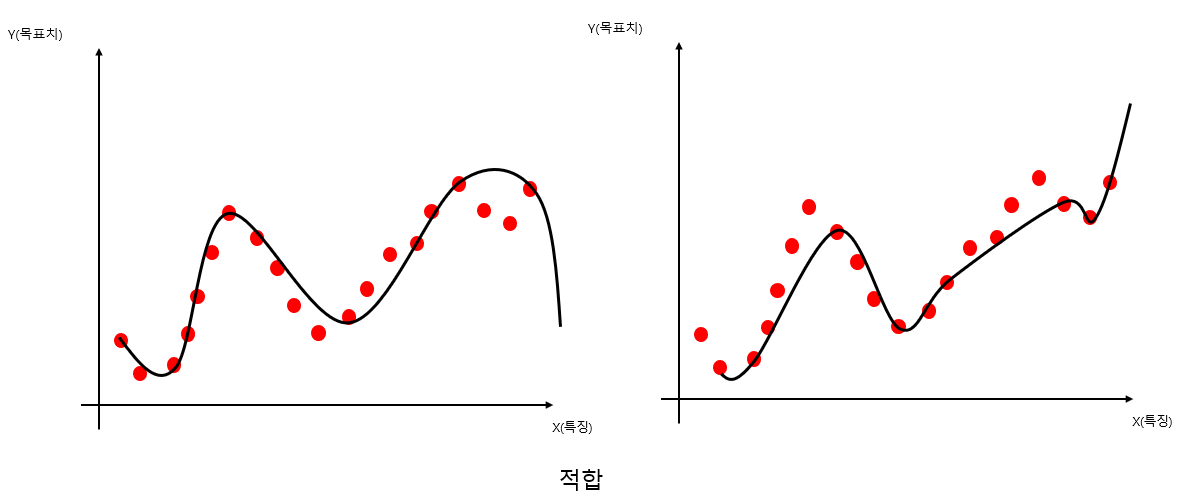
아래의 그림을 보면

바이어스의 희생을 최소로 유지하고, 분산을 최대로 낮춘 모델이 제일 적합한 모델임을 알 수 있다.
이렇게 되면 일반화 능력을 향상 시킬 수 있다.
많은 데이터 수집
과잉적응을 방지하는 방법 중 데이서 수집이 있다.

데이터를 많이 수집하게되면 일반화 능력이 향상 된다.
일반화 능력을 향상 시키기 위해 검증방법을 사용하게 된다.
검증집합과 교차검증
검증집합과 교차검증을 이용한 모델 선택 알고리즘
검증 :
훈련데이터 중 일부를 활용해서 검증, 검증 집합이 필요함
-> 훈련데이터 {a, b, c, d, e}가 있다고 하면
그 중 일부인 {a, c}를 검증데이터로 활용한다는 의미이다.
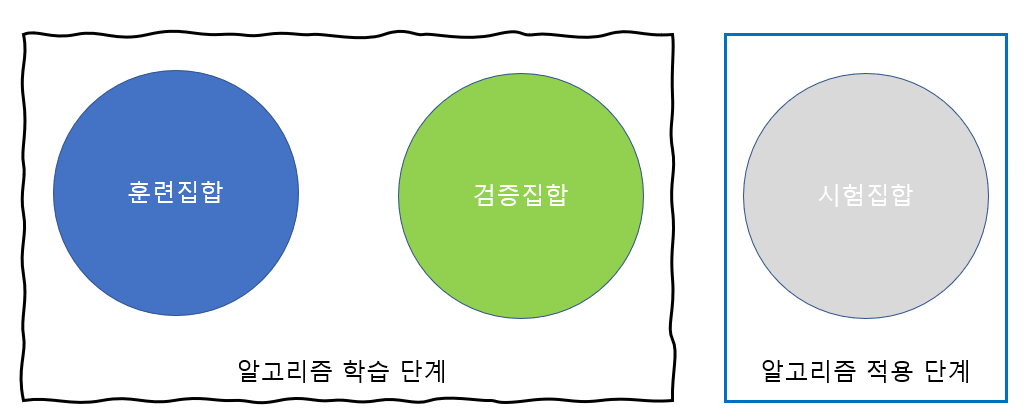
검증집합이 없는 경우는 교차검증 방식을 이용한다.
교차검증 :
비용 문제로 별도의 검증집합이 없는 상황에 유용한 모델을 선택하는 방법
훈련집합을 등분하여 학습과 평가 과정을 여러 번 반복한 후 평균을 사용한다.
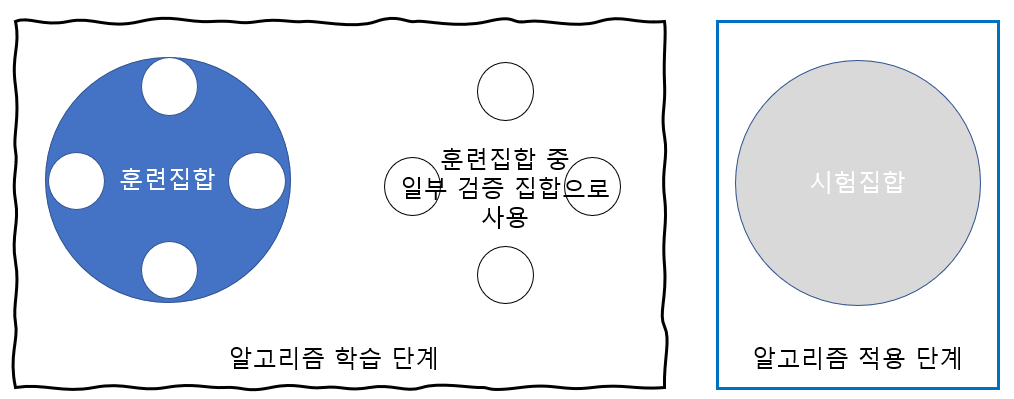
훈련집합을 균등하게 k등분 한 다음 그중 하나의 등분을 빼놓고 그것을 제외한 나머지를 가지고 훈련시킨다.
그 이후 검증 과정에서 빼놓은 집합으로 테스트 하는 방법
'0 + 자동차 > 0 + 자율주행' 카테고리의 다른 글
| [자율주행] 예제를 통해 알아보는 기계학습의 개념(선형모델) (0) | 2021.06.19 |
|---|---|
| [자율주행] 자율주행과 인공지능 개념 (0) | 2021.06.19 |