2022.05.15 - [컴퓨터 공학/0 +운영체제] - [운영체제] 7. Scheduling 기법
[운영체제] 7. Scheduling 기법
2022.05.03 - [컴퓨터 공학/0 +운영체제] - [운영체제] 6. Race Conditions(2) -Semaphores, Mutex and Monitors [운영체제] 6. Race Conditions(2) -Semaphores, Mutex and Monitors 2022.04.11 - [컴퓨터 공학/0..
howisitgo1ng.tistory.com
지난 포스팅에 이어서 운영체제의 스케줄링 기법에대해서 더 알아보자..!

유닉스 스케줄러
특징
- 각 우선순위 대기열 내에서 라운드 로빈을 사용한 다단계 피드백
- 실행 중인 프로세스가 차단되지 않거나 1초 이내에 완료되지 않으면 우선된다.
- 우선 순위는 초당 한 번씩 계산된다.
- 기본 우선 순위는 모든 프로세스를 우선 순위 수준의 고정 대역으로 나눈다.

nice는 유닉스 계역의 운영체제에서 찾아볼 수 있는 프로그램인데, 커널 호출에 직접 매핑된다.
nice는 특정 cpu 우선순위를 가진 유틸리티 또는 쉘 스크립트를 호출 하기위해 사용된다.
따라서, 프로세스에 다른 프로세스보다 더 많거나 더 적은 cpu 시간을 제공한다.
-20 niceness는 가장 높은 우선 순위이고 19가 가장 낮은 우선 순위 이다.
(niceness는 부모 프로세스에서 상속되고 보통 0이다. Pj(i)가 작을 수록 우선 순위가 높다.)
일반 사용자는 nice를 감소시킬 수 없다.(올릴 수는 있다.)
대역(Bands)
프로세스 별로 특정 대역에 소속되게 실행 시킬 수 있다.
- Swapper(우선 순위 높음)
- Block I/O device control
- File manipulation
- Character I/O device control
- User processes(제일 우선 순위가 낮은곳에서 실행)
BSD and SVR3 Scheduling
https://ko.wikipedia.org/wiki/BSD
BSD - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전.
ko.wikipedia.org
SVR(유닉스 시스템 V)은 유닉스 운영 체제의 최초 상용 버전 가운데 하나이다.
BSD는 미국 캘리포니아 대학교 버클리의 CSRG에서 개발한 유닉스 운영체제이다.
모든 클럭 틱은 프로세스의 p_cpu를 증가 시킨다.
매초 마다 프로세스의 우선순위가 다시 계산 된다.
두 운영체제의 차이점은 decay에 있다.
SVR3은 decay가 1/2라서 우선순위를 반으로 줄인다. 그래서 무거운 시스템에서는 기아 현상이 발생할 수 있다.
이러한 문제를 해결하기 위해 BSD가 개발 되었다.
BSD는 decay = (2*load_avg) / (2*load_avg + 1)을 사용한다.
load_avg는 실행하는 프로세스의 갯수 이다.
프로세스 실행하지 않으면 우선 순위를 재 계산한다.
p_userpri = PUSER + p_cpu/2 + p_nice
3 tasks, PUSER = 50, p_nice = 0, clock ticks = 60(매초)

리눅스 스케줄링(Linux Scheduling)
- SCHED_FIFO
- real-time threads
- SCHED_RR
- real-time threads
- SCHED_OTHER
- FIFO, RR보다 우선순위가 낮다.
- FIFO, RR 스케줄링이 없을때, OTHER를 실행한다.
- non-real-time threads
- FIFO, RR보다 우선순위가 낮다.
아래와 같은 우선순위를 갖고 있을때,
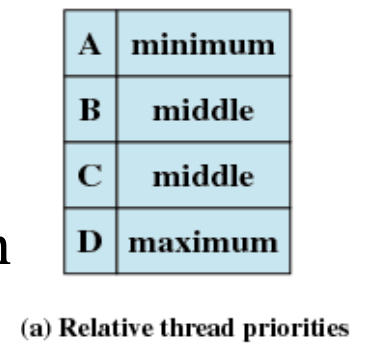
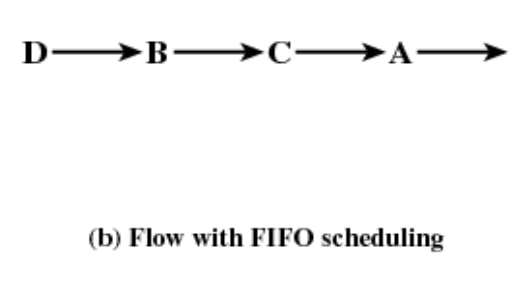
RR은 동일한 우선순위가 여러개 있을 때 돌아가면서 실행한다.
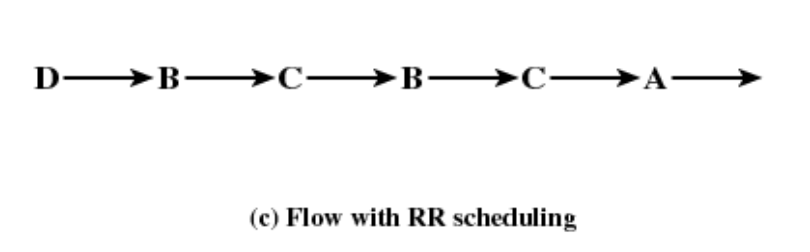
FIFO는 자신이 실행하고 싶은 만큼 실행한다.(스스로 멈출 때 까지: 멈추지 않으면 시스템 독점이 일어난다.)
O(1): Linux SCHED_OTHER Scheduling
알고리즘에서 O(1)은 가장 효율적인 시간복잡도를 의미한다.
기존의 알고리즘은 너무 복잡하고 overhead가 크다. 그래서 O(1) 스케줄링 등장!
O(1): Linux SCHED_OTHER Scheduling는그만큼 효율적인 스케줄러 인것을 의미한다.
적절한 프로세스를 선택하여 프로세서에 할당하는 시간은 시스템의 부하 또는 프로세서 수에 관계없이 일정하다.
0~139(140개)의 Q가 있습니다.
1. time slice를 소비하면 Expired Q로 이동
2. Active Q가 하나도 없으면 Expired Q가 Active Q로 이동한다.(여기서 우선순위가 재조정 된다.)
3. 1, 2가 반복된다.
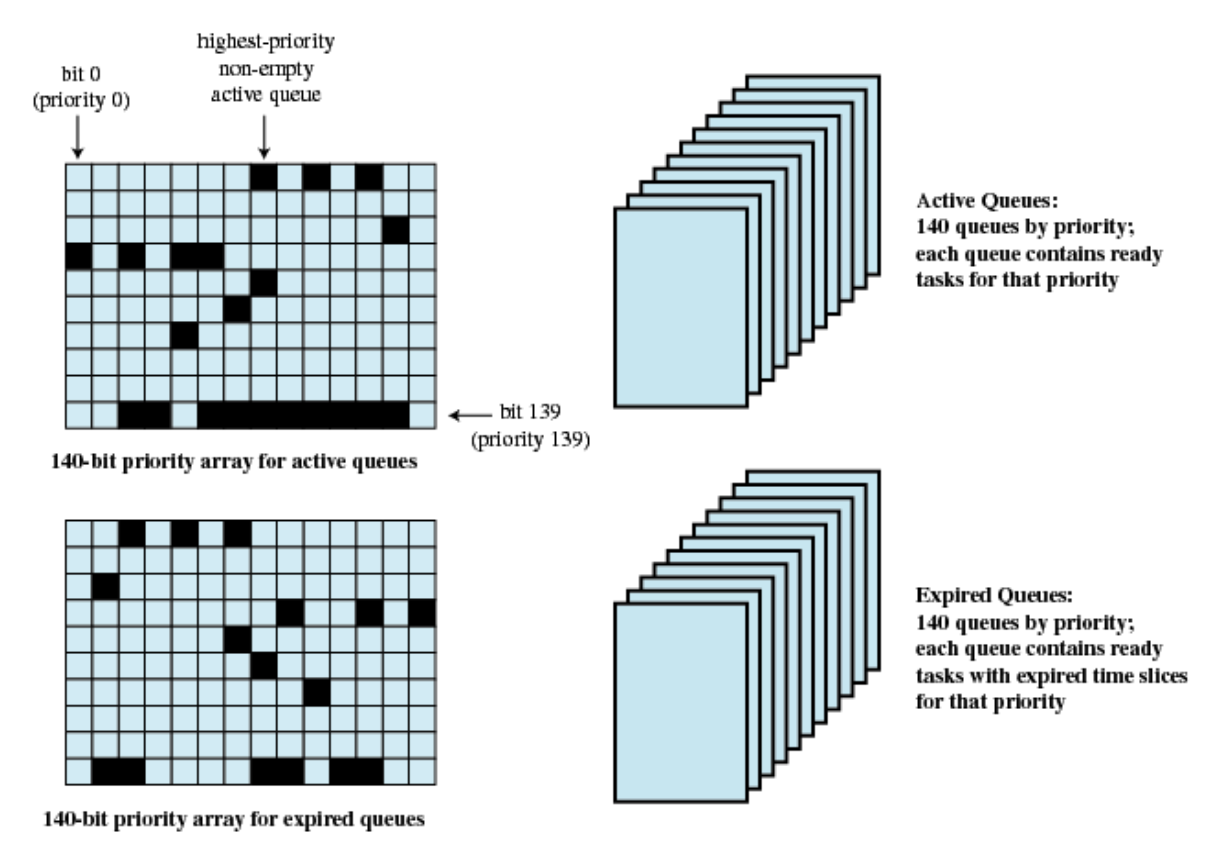
- 특징(task = thread)
- IO-bound process에게 높은 우선순위를 주는 정책
- task의 실행시간 대비 휴면시간 비율(sleep_avg)유지
- 우선순위와 타임슬라이스 계산식
- effectivce prio = 인터액티브 정도(sleep_avg로 계산) + 정적 우선순위(nice값에 비례 -음수가 우선순위가 더 높다.)
- 새로운 타임 슬라이스 = effective prio에 비례
- 인터액티브 태스크는 expired Q가 아닌 active Q에 넣는다.
- 문제점
- Nice값이 time_slice 절대값을 결정
- Nice 0인 2 태스크는 timeslice 100ms를 가지며 100ms 마다 문맥교환이 발생한다.
- Nice 20인 2 태스크는 timeslice 20ms를 가지며 20ms 마다 문맥교환이 발생한다.
- Nice 값의 차이가 timeslice 차이에 비례하지 않음
- Nice 0와 1의 timeslice는 100ms와 95ms
- Nice 18과 19의 timeslice는 10ms와 5ms
- Timeslice와 timertick의 granularity 문제(정밀도 문제)
- timeslice 5ms, timer interrupt주기가 10ms이면 5ms마다 진행이 안된다..
- Interactive task 우선 문제
- sleep에서 깨어나면 무조건 active Q로 들어온다.(너무 과하게 호의를 베푼다)
- Nice값이 time_slice 절대값을 결정
경우에 따라 의도한 바와 다르게 동작....ㅠ0ㅠ
RSDL(Rotating Staircase Deadline Scheduler)
- Con Kolivas가 O(1)스케줄러를 개선한 RSDL(Rotating Staircase Deadline Scheduler)개발
- I/O bound와 CPU bound프로세스 구분을 없애고 CPU 할당시간을 공평하게 분배한다.
CFS 스케줄러(Complete Fair Scheduler)
[OS] 프로세스 및 리눅스 스케줄링(CFS)의 이해
.
velog.io
http://egloos.zum.com/rousalome/v/9999939
[리눅스커널] 스케줄링: CFS 스케줄러를 이루는 주요 개념 알아보기
CFS(Completely Fair Scheduler)는 2.6.23 커널 버전 이후 적용된 리눅스의 기본 스케줄러입니다. CFS이란 용어를 그대로 풀면 ‘완벽하게 공정한 스케줄러’라고 해석할 수 있습니다. 즉, 런큐에서 실행 대
egloos.zum.com
CFS란 완벽하게 공정한 스케줄러라고 해석 할 수 있다.
즉 런큐에서 실행 대기 상태로 기다리는 프로세스를 공정하게 실행하도록 기회를 부여하는 스케줄러이다.
CFS를 이루는 주요 개념에 대해서 알아보자.
- 타임슬라이스(timeslice)
- 스케줄러가 프로세스에게 부여한 실행시간
- CFS는 프로세스마다 실행할 수 있는 단위 시간을 부여하는데 이를 타임슬라이라고 부른다.
- 프로세스는 주어진 타임슬라이스를 소진하면 문맥교환이 일어난다.
- 타임슬라이스를 사용하는 이유는 모든 프로세스가 최대한 cpu에서 실행할 수 있는 기회를 부여하기 위함이다.
- 스케줄러는 타임슬라이스로 프로세스 실행 시간을 관리한다.
- 프로세스 입장에서 타임슬라이스는 모래시계로 비유할 수 있다.
- 프로세스에게 부여된 타임슬라이스가 10ms이면, 프로세스가 5ms시간 동안 실행했다면, 5ms가 남은것
- CFS는 타이머 인터럽트가 발생했을 때 주기적으로 프로세스가 얼마난 타임 슬라이스를 소진하고 있는지 확인
- 우선순위
- CFS가 문백 교환시 다음 프로세스를 선택하는 기준 중 하나이다.
- 가장먼저 CPU에서 실행한다
- 더 많은 타임 슬라이스를 할당한다.
- 리눅스는 총 140단계의 우선순위를 제공한다.
- 0~99: RT(실시간) 프로세스
- 100 ~ 139: 일반 프로세스
- 프로세스마다 설정된 우선 순위를 기준으로 가상 실행 시간을 설정한다.
- CFS가 문백 교환시 다음 프로세스를 선택하는 기준 중 하나이다.
- 가상 실행 시간(vruntime)
- 프로스세스가 그 동안 실행한 시간을 정규화한 시간 정보이다.
- CFS가 프로세스를 선택 할 수 있는 load weight와 같은 여러 지표가 고려된 실행 시간이다.
- 설명
- Ingo Monlar가 개발했다.
- I/O bound와 CPU bound프로세스 구분을 없애고 CPU 할당시간을 공평하게 분배한다.
- Redun Q를 없애고 RB-tree(Red Block tree)를 사용했다.
- jiffies와 HZ상수를 이용하지 않고, nano sec단위로 동작한다.
- 통계적 기법이나 휴리스틱을 이용하지 않았다.
- 특징
- Nice 값에 비례하여 weight 할당, task들의 weight로부터 proportion of processor를 계산
- 프로세서 실행 시간이 100ms 일때 nice 값이 같은 task가 2개 이면 timeslice 50ms 할당, 4개이면 25ms할당
- Nice 값 차이가 weight차이와 비례
- Nice 0와 5의 weight는 1024와 335, 각 태스크의 weight 비율은 1024/(1024+335), 335/(1024+335)로 약 3:1이다.
- Nice 5와 10의 weight 비율도 약 3:1 이다.
- Virtual Runtime(timeslice와 timetrick의 granularity문제 해결)
- 문맥교환 주기가 20ms, 두 태스크가 45ms, 15ms씩 (3:1 비율) 수행해야 하면, 실제로는 40ms, 20ms 수행한다.
- 다음 스케줄 주기에 수행시간 (40ms, 20ms)에 scale factor(1:3)을 곱하여 virtual runtime을 구한다.
- 두 태스트의 virtual runtime(40ms, 60ms)이 같지 않으면 뒤쳐진 태스크(40ms)를 수행하여 시간을 보상한다.
- Sleep에서 깨어난 태스크의 virtual runtime을 현재 실행되고 있는 태스크가 가진 virtual runtime을 현재 실행되고 있는 태스크가 가진 virtual runtime 중 가작 작은 값으로 설정(약간 보정)
- Nice 값에 비례하여 weight 할당, task들의 weight로부터 proportion of processor를 계산
CFS Run Q
RB tree 사용, 태스크를 virtual runtime 기준으로 정렬
RB treedml key: se -> vruntime - cfs - rq -> min_vruntime
RB tree 에서 가장 작은 vruntime을 가진 태스크 RB tree에서 제일 왼쪽 태스크) 실행
Scheduling lantency period
모든 runable task가 적어도 한 번 실행되기 위한 interval
if (nr_running < sched_nr_latency) period= 6 ms; //sched_nr_latency (default: 8)
else period = sched_nr_latency * sysctl_sched_min_granularity; // (default: 0.75ms)
태스크의 timeslice와 vruntime 갱신
timeslice = (se -> load.weight / cfs_rq -> load.weight) * period
vruntime += (NICE_0_LOAD / se-load.weight) * delta_exec
delta_exec: 태스크가 실제 cpu에서 실행된 시간
NICE_0_LOAD: 1024
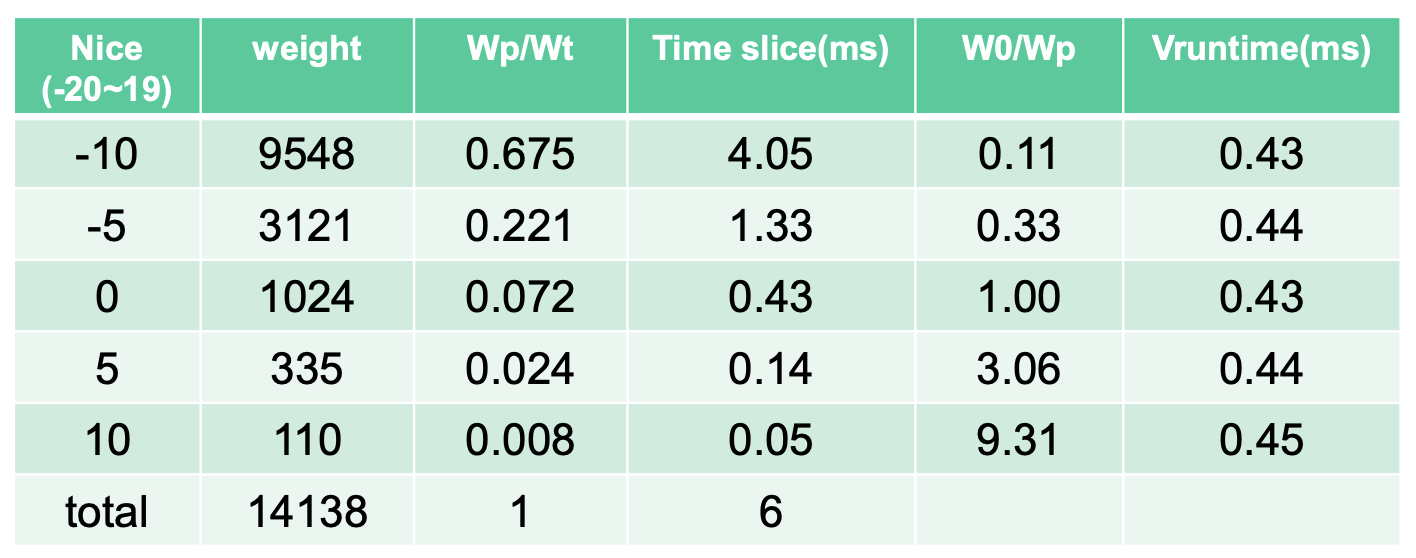
스케줄링예
- nr_running = 5, scheduling latency = 6ms
- Wp: task weight
- Wt: rq의 total weight
- W0: 1024
UNIX SVR4 Scheduling
- 실시간 프로세스에 대한 최상의 선호도
- 커널 모드 다음으로 높은 프로세스
- 다른 사용자 모드 프로세스보다 선호도가 낮음
- 선점 가능한 정적 우선 순위 스케줄러
- 세 가지 우선 순위 클래스로 나누어진 160개의 우선 순위 수준 집합 소개
- Real time(159 - 100)
- 제일 먼저 실행
- Kernel(99 - 60)
- Time-shared(59 - 0)
- 제일 나중에 실행
- Real time(159 - 100)
- 선점 삽입(Insertion of preemption points)
- 프로세스가 실행하다가 시스템 호출 할때(I/O)
인터럽트를 걸어서 인터럽트 서비스 호출(운영체제 커널)
데이터를 갖고 리턴 전에 스케줄링 실행(원래 프로세스로 돌아갈수도 있고, 다른 프로세스로 돌아갈 수도 있다.) - 돌아가기 직전에 스케줄링 한다.(단점으로 시간이 오래걸림)
- 그래서 중간중간 스케줄하는 코드(Insertion of preemption points)를 넣어 시스템 반응성을 올렸다.
- 프로세스가 실행하다가 시스템 호출 할때(I/O)
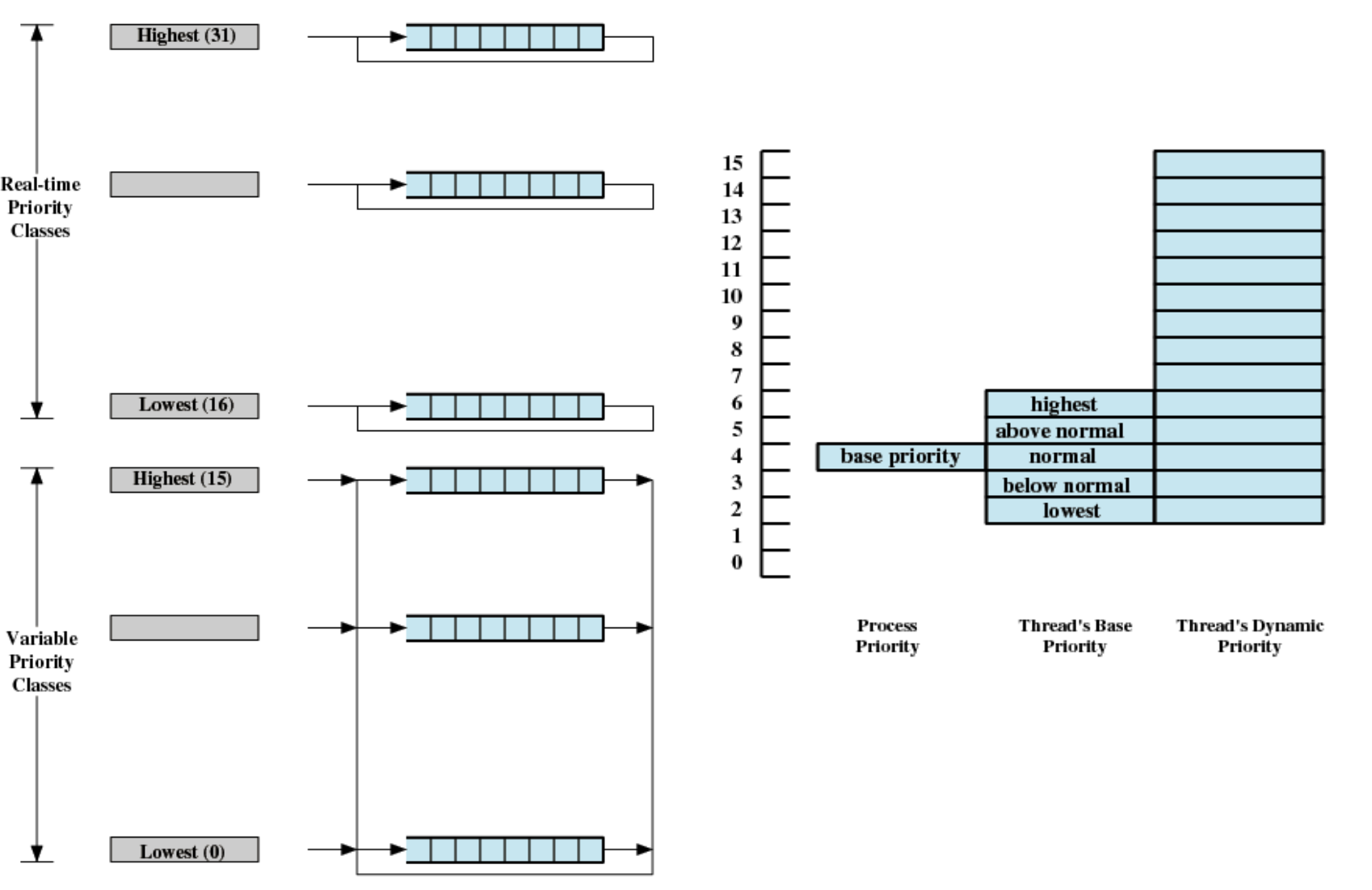
Windows Scheduling
- 두 개의 밴드 또는 클래스로 구성된 우선순위
- Real time
- Variable
- 우선 순위 기반 사전 스케줄러(Priority-driven preemptive scheduler)
스레드 우선순위를 동적으로 변화시키면서 스케줄링 한다.
식사하는 철학자들의 문제(Dining Philosophers Problems)
동시성과 교착 상태를 설명하는 예시로, 여러 프로세스가 동시에 돌아갈 때 교착 상태가 나타나는 원인을 알아보자.
식사하는 철학자 문제 - 나무위키
5명의 철학자가 원탁에 앉아서 식사를 한다. 철학자들 사이에는 포크가 하나씩 놓여 있고, 철학자들은 다음의 과정을 통해 식사를 한다. 1. 일정 시간 생각을 한다.2. 왼쪽 포크가 사용 가능해질
namu.wiki
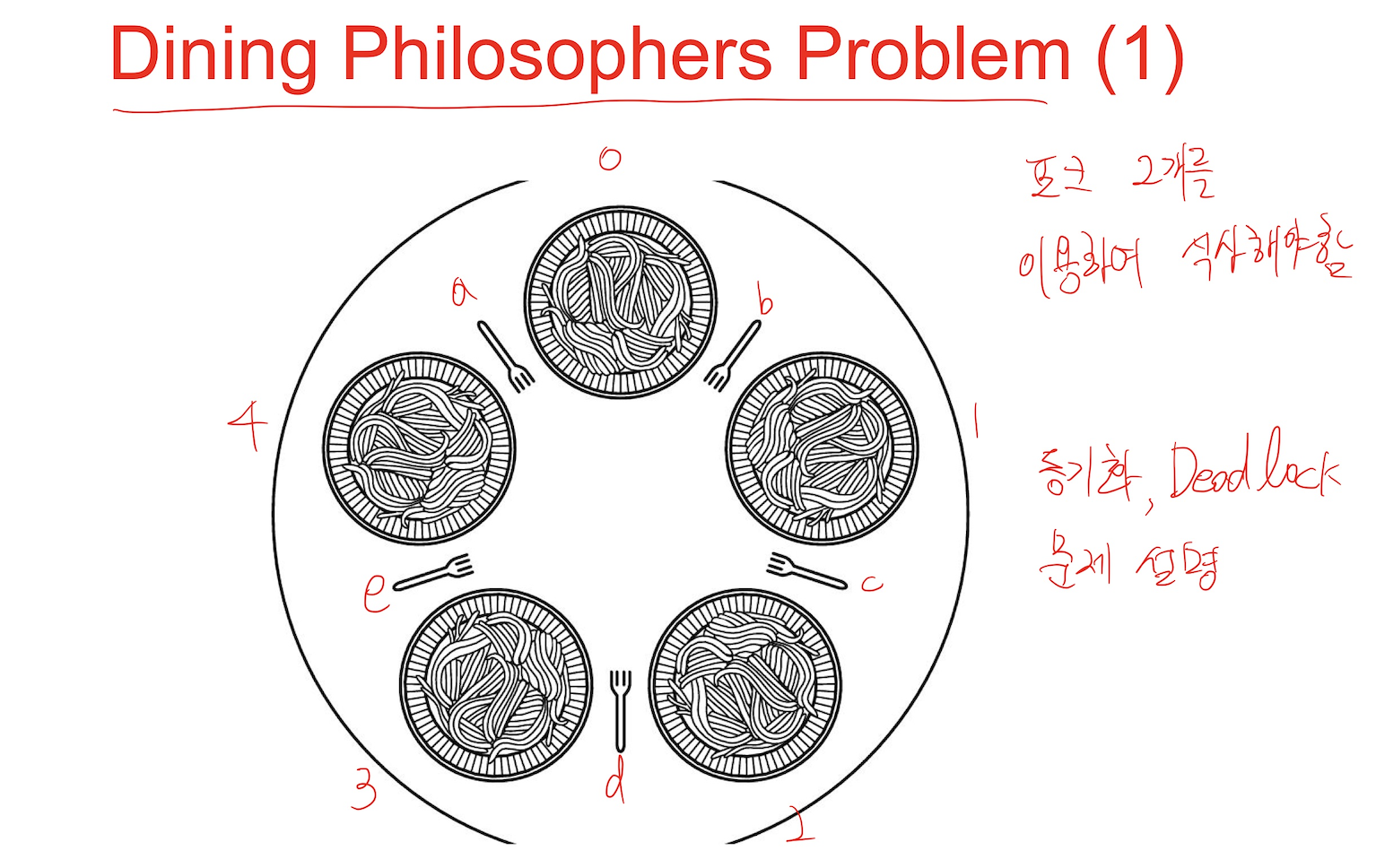

모든 철학자가 식사를 하기위해 왼쪽 fork를 집었을 경우...(take_fork(i);)
모두 굶어 죽는다.(옆에 있는 철학자가 포크를 집어 갔기 때문에...)

해결 방법으로는 여러가지가 있는데 짝수 철학자와 홀수 철학자로 나누면 된다.
첫번째 포크에서는 경쟁하고 두번째 포크부터는 경쟁하지 않는다.
Readers and Writers Problem


'컴퓨터과학 > 0 +운영체제' 카테고리의 다른 글
| [운영체제] 10. 가상 메모리 (0) | 2022.06.16 |
|---|---|
| [운영체제] 9. 메모리 관리 (0) | 2022.06.13 |
| [운영체제] 7. Scheduling 기법 (0) | 2022.05.15 |
| [운영체제] 6. Race Conditions(2) -Semaphores, Mutex and Monitors (0) | 2022.05.03 |
| [운영체제] 5. Race Conditions(1) (0) | 2022.04.11 |