Redis 특징

In-memory
- 모든 데이터를 ram 에 저장(backup / snapshot 제외)
Sigle thread
- 단일 thread 로 모든 task 를 처리
Cluster mode
- 다중 노드에 데이터를 분산 저장하여 안정성과 고가용성을 제공
- 안정성: Redis는 고속으로 데이터를 읽고 쓰는 데 최적화되어 있지만, 트래픽이 급증하면 단일 노드로 처리하기 어렵습니다.
- 고가용성: 만약 마스터 노드가 장애가 발생하면, 클러스터 내 슬레이브 노드 중 하나가 자동으로 승격되어 마스터 역할을 대신합니다. 이를 통해 서비스 중단을 최소화합니다.
- 마스터 노드는 데이터를 저장하고 처리하며, 슬레이브 노드는 복제본을 유지
Persistence
- RDB(
Redis Database) + AOF(Append only file) 통해 영속성(Persistence) 옵션 제공 - RDB(
Redis Database)- Point-in-time snapshot 재난 복구 또는 복제에 주로 사용합니다.
- 일부 데이터 유실의 위험이 있고, 스냅샷 생성 중 클라이언트 요청 지연이 발생합니다.
- AOF(
Append only file)- Redis 에 적용되는 쓰기(
write) 작업을 모두log로 저장합니다. - 데이터 유실의 위험이 적지만, 재난 복구시
write작업을 다시 적용하기 때문에 rdb 보다 느림
- Redis 에 적용되는 쓰기(
- 영속성(
Persistence)- redis는 주로 캐시에 사용되지만, ssd 같은 영구적인 저장 장치에 데이터를 저장할 수 있습니다.
Pub/Sub
- pub/sub 패턴을 지원하여 손쉬운 애플리케이션 개발
sub 명령어
$ subscribe news
1) "subscribe"
2) "news"
3) (integer) 1
$ (subscribed mode)- subscribe [channel] 문법
pub 명령어
$ publish news "today is lunar new years!"
(integer) 1- publish [channel] [message] 문법
sub 결과
$ (subscribed mode)>
1) "message"
2) "news"
3) "today is lunar new years!"
Redis 설치
MacOS
https://redis.io/docs/getting-started/installation/install-redis-on-mac-os/
- HomeBrew 설치
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"- Redis 설치
brew install redis- Redis 실행
brew services start redis- Redis 종료
brew services stop redis
Windows
https://redis.io/docs/getting-started/installation/install-redis-on-windows/
- Redis 설치
curl -fsSL https://packages.redis.io/gpg | sudo gpg --dearmor -o /usr/share/keyrings/redis-archive-keyring.gpgecho "deb [signed-by=/usr/share/keyrings/redis-archive-keyring.gpg] https://packages.redis.io/deb $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/redis.list
sudo apt-get updatesudo apt-get install redis- Redis 실행
sudo service redis-server start
Redis 활용
Caching(임시 데이터)
- 임시 비밀번호(One Time Password)
- 로그인 세션
Rate Limiter
- API에 대한 요청 횟수를 제한하기 위해 사용
Message Broker
- Lists, Streams 같은 데이터 타입을 활용하여 메시지 브로커를 구현
실시간 분석 / 계산
- 순위표(Leaderboard)
- 반경 탐색(Geofencing)
- 방문자 수 계산(Visitors Count)
실시간 채팅
- Pub / Sub 패턴
Redis 데이터 타입 😇
- Strings
- Lists
- Sets
- Hashes
- Sorted Sets
- Streams
- Geospatial
- Bitmaps
- HyperLogLog
- BloomFilter
시간이 조금 걸리더라도 실습을 함께 진행하는 것을 추천 드립니다~! 🙌
Strings
- 문자열, 숫자, serialized object(JSON string) 등 저장
- redis 는 별도의 integer 타입 없이 String으로 숫자를 저장
- 숫자의 형태로 String 을 저장할 경우 별도의 더하기(
incr) 빼기(decr) 연산이 가능
명령어
set
$ set member ralph
(integer) 1
$ set member '{"name": "ralph", "language": "ko"}'
(integer) 1
$ set member:ralph:age 30
(integer) 1member라는 key로ralph문자열(value) 저장- redis 는 JSON String 을 직접 저장 가능
- 사용할 때 해당 데이터를 직접 JSON 으로 변환해서 사용해야 함
- redis 에서는 일반적으로 key를 만들 때 콜론(:)을 이용하여 구분
member:ralph:age가 key 인 값(value)은“30"으로 저장
mset
$ mset age 31 language koage라는 key로"31"값(문자열) 저장,language라는 key로ko문자열(value) 저장
mget
$ mget member age language- 다수의 key(
member,age,language)의 값(value)을 한번에 조회
incr / decr
$ incr price
$ decr priceincr명령어는 key 값(value)을 1 증가,decr명령어는 key 값(value)을 1 감소
incrby | decrby
$ incrby price 10
$ decrby price 5- 숫자형 String 값에 특정 값을 더하거나(
incrby) 뺄(decrby) 때 사용
Lists
- Strings 을 Linked List 로 저장
- 데이터 양끝에 데이터를 추가하거나 삭제하는 것에 최적화
- push / pop 최적화 O(1)
- Queue(FIFO) / Stack(FILO) 구현에 사용

명령어
lpush
$ lpush jobs job1 job2 job3
(integer) 3- lpush 명령어로 jobs 에 job1, job2, job3를 저장
rpop
$ rpop jobs
"job1"
$ rpop jobs
"job2"
$ rpop jobs
"job3"rpop을 사용하면queue자료구조 처럼 사용 가능
lpush
$ lpush jobs job1 job2 job3
(integer) 3- lpush 명령어로 jobs 에 job1, job2, job3를 저장
lpop
$ lpop jobs
"job3"
$ lpop jobs
"job2"
$ lpop jobs
"job1"lpop을 사용하면stack자료구조 처럼 사용 가능
lrange
$ lrange jobs -2 -1
1) "job2"
2) "job1"- lrange 명령어로 index 를 사용하여 조회 가능
- lrange [key] [startIndex] [StopIndex] 의 문법
- 일반적으로 startIndex <= stopIndex 조건 만족
ltrim
$ ltrim jobs 0 1- 지정한 범위(0 ~ 1)의 데이터만 남기고 나머지 모두 삭제할 때 사용
Sets
- Unique String 을 저장하는 정렬되지 않은 집합
- Set Operation 사용 가능(e.g. intersection, union, difference)
- intersection: 교집합(
sinter) - union: 합집합()
- difference: 차집합(
sdiff)
- intersection: 교집합(
명령어
sadd
$ sadd user:1:fruits apple banana orange orange
(integer) 1
$ sadd user:2:fruits apple lemon
(integer) 1- Sets 자료구조의 특성으로 orange 를 중복으로 저장해도 1개만 저장
smemebers
$ smemebers user:1:fruits- Sets의 모든 데이터 출력
scard
$ scard user:1:fruits- Sets의 카디널리티(Cardinality) 출력
- 카디널리티(Cardinality): 특정 데이터 집합의 유니크(Unique)한 값의 개수
sismember
$ sismember user:1:fruits banana- 특정 데이터가 sets 에 포함되었는지 확인
sinter
$ sinter user:1:fruits user:2:fruits
"apple"- user:1 과 user:2 가 공통으로 갖고 있는 과일 출력
diff
$ diff user:1:fruits user:2:fruits
1) "banana"
2) "orange"- user:1 에는 있지만 user:2 에는 없는 과일 출력
sunion
$ sunion user:1:fruits user:2:fruits
1) "banana"
2) "orange"
3) "apple"
4) "lemon"- user:1 과 user:2에 존재하는 모든 과일 출력
Hashes
- field-value 구조를 갖는 자료구조
- 다양한 속성을 갖는 객체의 데이터를 저장할 때 유용
명령어
hset
$ hset member name ralph age 31 language ko hset [key] [field] [value] [field] [value] [field] [value] …명령어로 저장
hget
$ hget member name
"ralph"- hget 명령어로 해당 key의 field 의 값(value) 조회
hmget
$ hmget member name age language
1) "ralph"
2) "31"
3) "ko"- hmget 명령어로 해당 key의 다수의 field 의 값(value) 조회
hincrby
$ hincrby member age 10
(integer) 41
$ hincrby member name 100
(error) ERR hash value is not an integer
$ hdecrby member age 5
(error) ERR unknown command 'hdecrby', with args beginning with: 'member' 'age' '5'- 값(value)를 원하는 값 만큼 증가 또는 감소(음수 사용)
- 숫자형 String 에만 사용이 가능함
- 주의: hdecrby 명령어는 존재하지 않음
Sorted Sets(ZSets)
- Unique String 을 연관된
score를 통해 정렬된 집합(Set의 기능 + 추가로 score 속성 저장) - Sets의 특성에 추가적으로
score라는 field 를 갖고 있다고 생각하면 이해하기 쉬움 - 내부적으로
Skip List+Hash Table로 이루어져 있고,score값에 따라 정렬 유지score값이 동일하다면 lexicographically(사전 편찬 순) 정렬

명령어
zadd
$ zadd points 10 TeamA 10 TeamB 50 TeamC
(integer) 3- zadd [key] [score] [value] 문법
zrange
$ zrange points 0 -1
1) "TeamA"
2) "TeamB"
3) "TeamC"
$ zrange points 0 -1 rev withscores
1) "TeamC"
2) "50"
3) "TeamB"
4) "10"
5) "TeamA"
6) "10"- zrange [key] [startIndex] [StopIndex] [option] 문법
rev withscores옵션을 사용하면 역순으로score도 함께 조회
zrank
$ zrank points TeamB
(integer) 1
$ zrank points TeamA
(integer) 0- zrank [key] [value] 문법
- 해당 아이템의 랭킹을 반환
- 랭킹은 0부터 시작(인덱스 값)
Streams
append-only log에consumer groups과 같은 기능을 더한 자료구조append-only log는 데이터를 오직 추가(append)만 할 수 있는 자료구조consumer groups는 Kafka 와 같은 이벤트 스트리밍 플랫폼, 메시징 시스템에서 사용되는 개념
unique id를 통해 하나의 entry를 읽을 때, O(1) 시간 복잡도- Consumer Group을 통해 분산 시스템에서 다수의 consumer가 event를 처리

명령어
xadd
$ xadd events * action like user_id 1 product_id 1
"1737878508938-0"- xadd [key] [id] [field] [value] 문법
- id는 지정할 수 있지만 일반적으로
*(asterisk)를 사용
- id는 지정할 수 있지만 일반적으로

xrange
$ xrange events - +
1) 1) "1737878508938-0"
2) 1) "action"
2) "like"
3) "user_id"
4) "1"
5) "product_id"
6) "1"-
-
- 는 해당 key의 모든 데이터를 조회
-
xdel
$ xdel events 1737878508938- 데이터를 삭제
엇?! Streams는 append-only log 라서 데이터를 오직 추가만 할 수 있는 자료 구조 아닌가요? 🤔
append-only log라고 하면 데이터의 불변성을 유지하는 자료구조를 말합니다.
따라서 보통 데이터를 추가한 이후에 수정이나 삭제가 불가능합니다.
다만 append-only log라고 할지라도 저장 공간의 한계로 인해 계속해서 모든 데이터를 보관하지 않고, 데이터를 압축하거나 불필요한 데이터를 삭제하는 식으로 저장 공간을 확보합니다. (특히나 Redis의 경우 메모리를 활용하기 때문에 저장 공간을 효율적으로 관리하는 것이 더 중요합니다.)
Redis Streams의 경우는 이미 추가된 데이터를 수정하거나 데이터를 중간에 삽입할 수 없기 때문에 append-only log의 데이터 불변성 특성을 따르면서도, 실시간 데이터 관리와 저장 공간 효율성을 위한 유연한 삭제 기능을 추가적으로 제공한다고 볼 수 있습니다.
정리하자면 Redis Streams는 append-only log의 기본 개념을 확장한 유연한 데이터 구조 정도로 이해하시면 될 것 같습니다! 👍
Geospatials
- 좌표를 저장하고, 검색하는 데이터 타입
- 거리계산, 범위 탐색 등을 지원
명령어
geoadd
$ geoadd seoul:station 126.923917 37.556944 hong-dae 127.027583 37.497928 gang-nam- geoadd [key] [경도 | longitude] [위도 | latitude] [city]
- 흔히 위도, 경도 이런식으로 사용하지만 redis 에서는 경도를 먼저 추가해야합니다!
geopos
$ geopos seoul:station hong-dae
1) 1) "126.92391961812973022"
2) "37.55694440751653929"- 해당 key의 city의 위도와 경도 조회
geodist
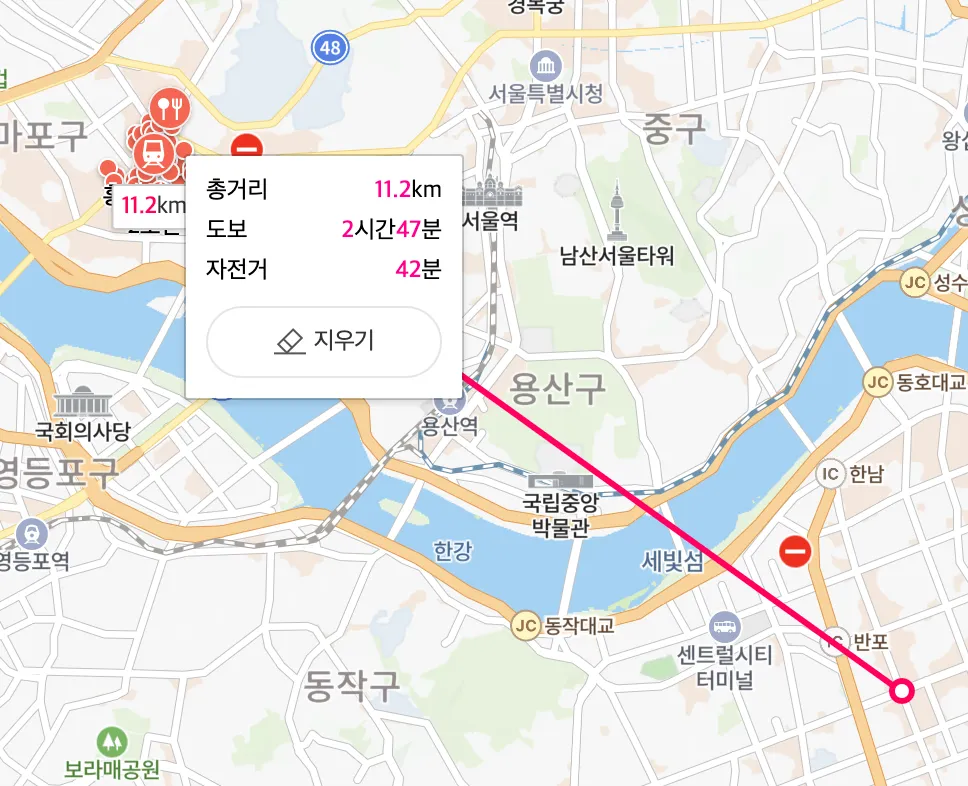
$ geodist seoul:station hong-dae gang-nam KM
"11.2561"- city 사이의 거리를 구할 수 있음
Bitmaps
- 실제로 존재하는 자료구조는 아니고, Strings 에 binary operation 을 적용한 것
- 최대 42억 binary 데이터 표현(2^32)
- 메모리를 조금 사용하기 때문에 바이너리 상태값을 저장하는데 많이 활용
- true, false 같이 여부 확인용
명령어
setbit
$ setbit user:log-in:25-01-01 123 1
(integer) 0
$ setbit user:log-in:25-01-01 456 1
(integer) 0
$ setbit user:log-in:25-01-02 123 1
(integer) 0- setbit [key] [offset] [value] 문법
- 1명의 user를 1개의 offset으로 표현
getbit
$ getbit user:log-in:25-01-01 123
(integer) 1- getbit [key] [offset]
- bit 값 조회
$ bitcount user:log-in:25-01-01
(integer) 2
bitcount user:log-in:25-01-02
(integer) 1- bitcount [key]
- 1인 bit 수를 카운트
bitop
$ bitop and result user:log-in:25-01-01 user:log-in:25-01-02
(integer) 58- bitop [연산자] [저장될 key] [key1] [key2] 문법
- key1과 key2의 연산결과를 저장될 key에 저장함
user:log-in:25-01-01의 bit가 1이고user:log-in:25-01-02에 bit가 1인 결과를 result에 저장
bitcount
$ bitcount result
(integer) 1user:log-in:25-01-01,user:log-in:25-01-02에 로그인한 회원은 1명
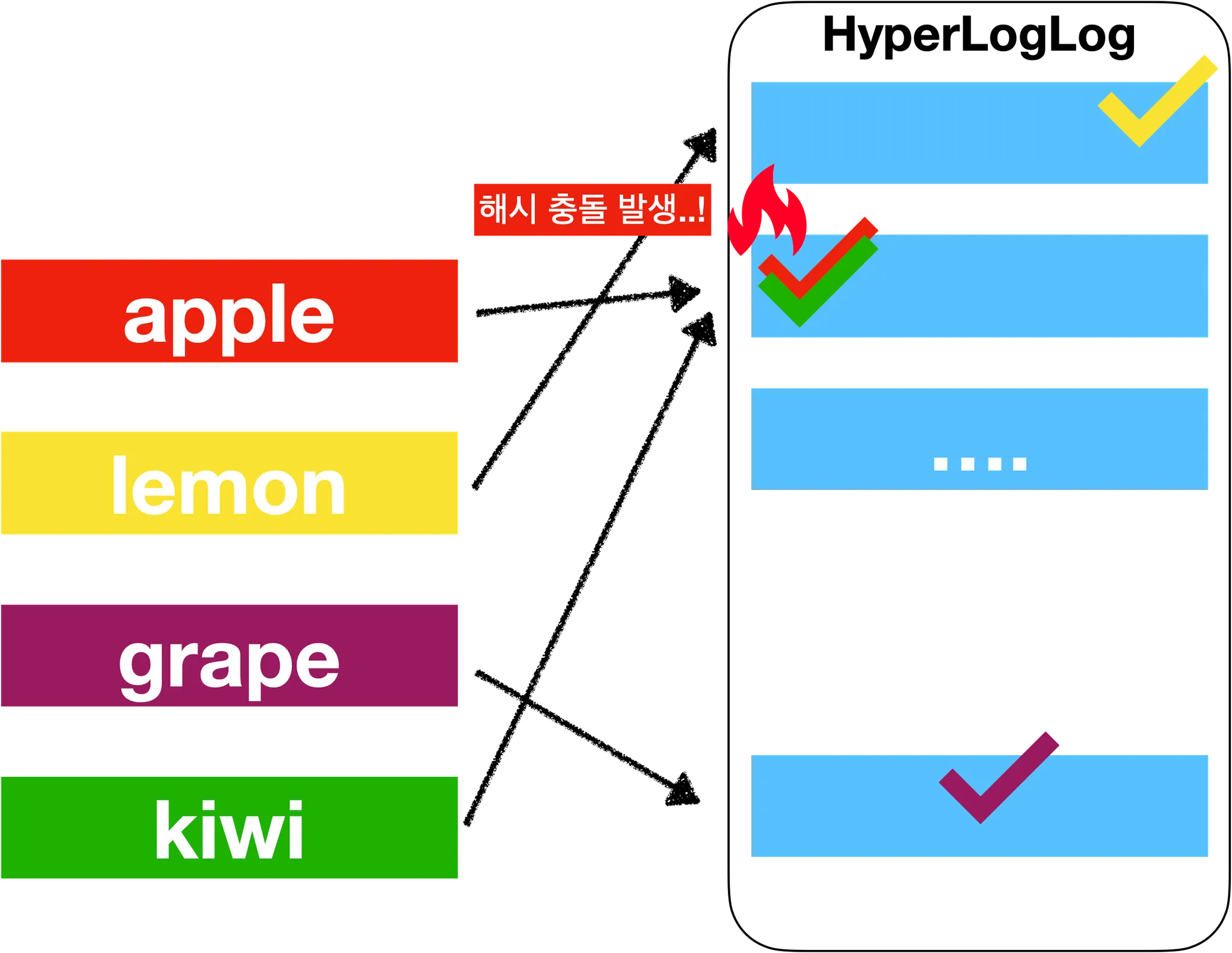
HyperLogLog
- 집합의
cardinality를 추정할 수 있는 확률형 자료구조 - 쉽게 이야기 하면 고유 값을 "추정"하는 계산기
- 결과 값이 실제와 오차가 발생할 수 있다는 의미
- 정확성을 일부 포기하는 대신 저장공간을 효율적으로 사용(평균 에러 0.81%)
- 실제 값을 저장하지 않음
- 모든 아이템을 출력하는 경우 부적합
- 해싱과 비트 패턴을 사용하여 고유 값을 계산
- 해싱으로 고유 값 계산
- e.g) "apple" →
10101011, "banana" →11001100
- e.g) "apple" →
- 해싱을 사용하면 입력 데이터의 길이와 관계없이 고정된 크기의 해시 값 생성
- 해시 값에서 앞부분의 0의 갯수로 고유 값 추정
01101011→ 0이 1개00111010→ 0이 2개00001111→ 0이 4개
- 해시 함수는 데이터를 랜덤하게 분산시키는 역할을 합니다.
- 고유 값이 많아질수록, 해시 값이 드문 패턴(예: 앞자리 0이 매우 많은 값)을 가지는 확률이 높아집니다.
- 고유 값이 적을 때:
- 데이터가 적으니
000000xx같은 간단한 해시 값만 나옵니다. (앞자리 0이 적음)
- 데이터가 적으니
- 고유 값이 많아질 때:
- 데이터가 많아지면서
00000000xxxxxx같은 해시 값이 나오게 됩니다. (앞자리 0이 많음)
- 데이터가 많아지면서
- 고유 값이 적을 때:
- 고유 값이 많아질수록, 해시 값이 드문 패턴(예: 앞자리 0이 매우 많은 값)을 가지는 확률이 높아집니다.
- 따라서 HyperLogLog는 데이터의 정확한 값을 저장하지 않고, 해시 값의 앞자리 0 개수만 기록
- 0이 4개 이면 → 2^4 →16개의 고유 값이 있다고 “추정”
- 여기서 근간에 확률적 계산식이 들어가서 최적화 해줌
- 해싱으로 고유 값 계산
명령어
pfadd
$ pfadd fruits apple lemon grape kiwi
(integer) 1- pfadd [key] [element] 문법
key에element저장
pfcount
$ pfcount fruits
(integer) 4- pfcount [key] 문법
key의cardinality조회
HyperLogLog 성능
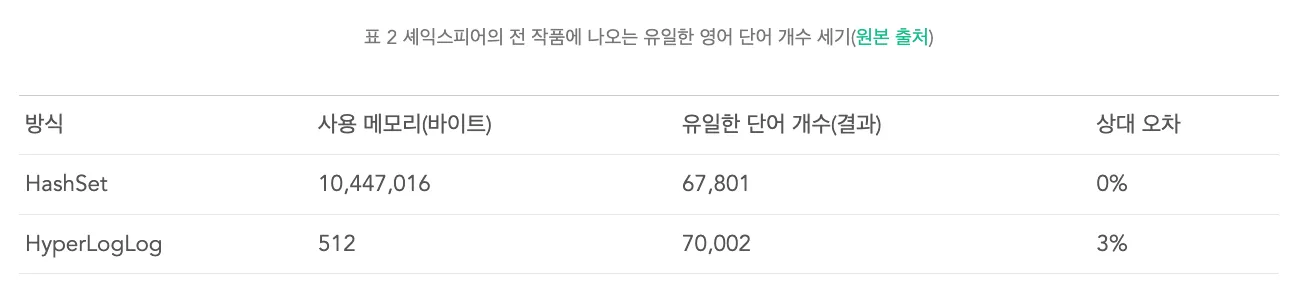
성능 비교 실습
Sets 에 1,000 개의 데이터 넣기
$ for ((i=1; i<=1000; i++)); do redis-cli sadd k1 $i; done
(integer) 1
(integer) 1
...
(integer) 1Sets 메모리 사용량 조회(bytes)
$ memory usage k1
(integer) 48304Sets 고유 값 조회
$ scard k1
(integer) 1000HyperLogLog 에 1,000개의 데이터 넣기
$ for ((i=1; i<=1000; i++)); do redis-cli pfadd k1 $i; done
(integer) 1
(integer) 0
...
(integer) 1HyperLogLog 메모리 사용량 조회(bytes)
$ memory usage k2
(integer) 2616- Sets 보다 약 95% 메모리 사용률 감소
- 2616 / 48304 * 100 = 5.4%
- 메모리 약 18배 절약!
HyperLogLog 고유 값 조회
$ pfcount k2
(integer) 1001- 오차 발생
BloomFilter
element가 집합 안에 포함되었는지 확인할 수 있는 확률형 자료구조(membership test)- 정확성 일부를 포기하는 대신 저장공간을 효율적으로 사용
false positive존재element가 집합에 실제로 포함되지 않은데 포함되었다고 잘못 예측하는 경우가 존재
false negative존재하지 않음element가 집합에 실제로 포함되었는데 포함되지 않았다고 잘목 예측하는 경우는 존재하지 않음
false positive,false negative예시- [
aa,bb,cc,dd] 라는 집합을 Bloom Filter 를 이용해서 저장하면 집합 안에kk라는 원소가 있는지 확인할 때 있다고 할 수 있음(false positive),aa라는 원소가 있는지 확인 했을 때 없다고 하는 경우는 없음(false negative)
- [
- 실제 값을 저장하지 않기 때문에 매우 적은 메모리 사용
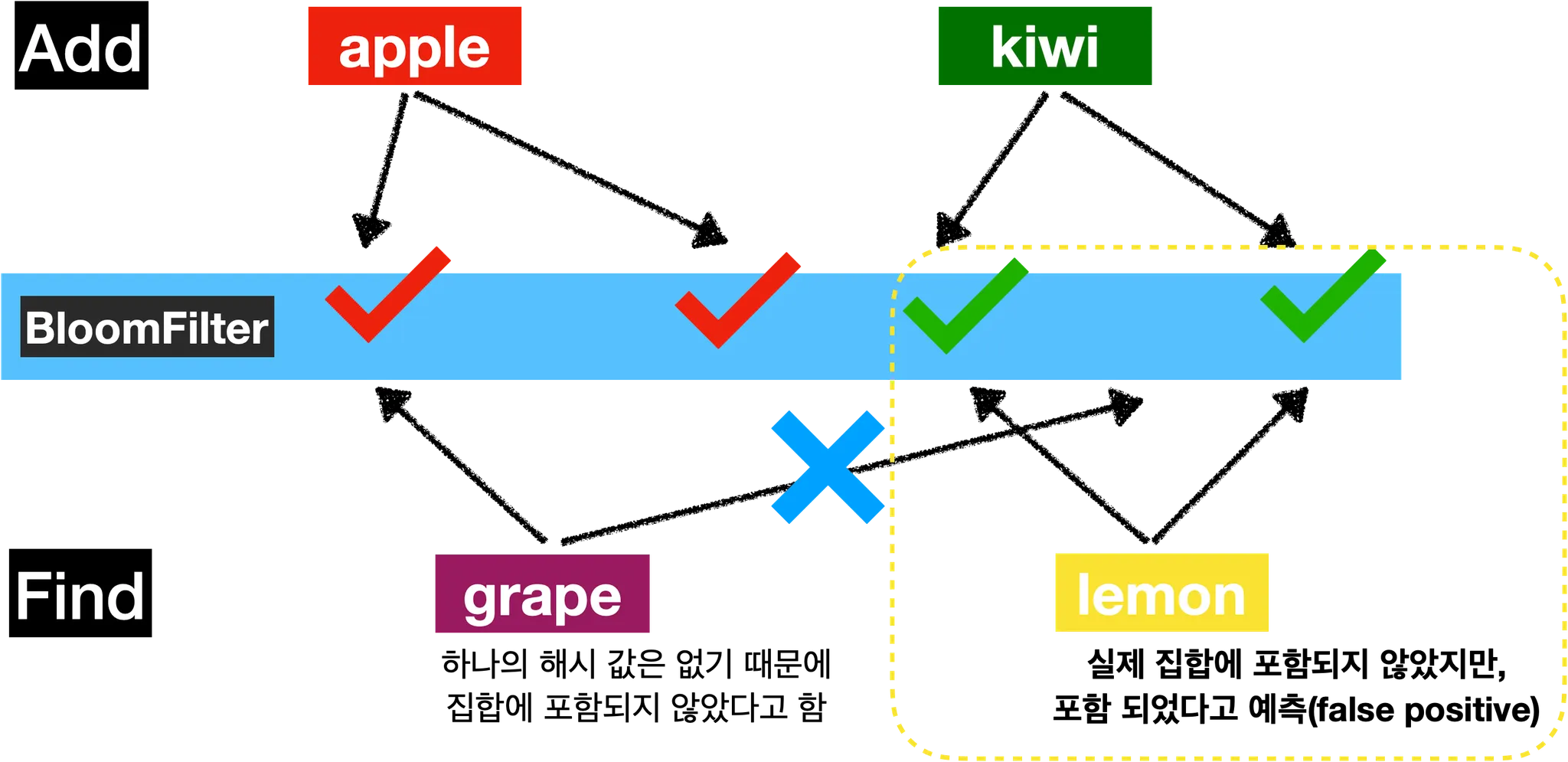
BloomFilter동작 원리BloomFilter는 값을 해싱하여 여러개의 해시 키를 생성- 여러 개의 key 에 해당하는 위치를
BloomFilter에 표시apple,kiwi를 BloomFilter 에 해시 값으로 저장
- 이후 어떤 아이템이 존재하는지 여부를 확인할 때는 다시 해시 키를 생성하여 해당 위치를 확인
grape,lemon이 집합에 존재하는지 확인lemon은false positive가 발생한 예시
- Bloom Filters by Example
Bloom Filters by Example
简体中文 Bloom Filters by Example A Bloom filter is a data structure designed to tell you, rapidly and memory-efficiently, whether an element is present in a set. The price paid for this efficiency is that a Bloom filter is a probabilistic data structu
llimllib.github.io
BloomFilter 를 사용하기 위해서는 별도의 모듈 설치가 필요!
하지만, 도커를 이용하면 바로 실습이 가능합니다. 😙
- Mac
- Windows
docker image 다운로드 + container 실행
$ docker run -p 63790:6379 -d --rm redis/redis-stack-serverredis-cli 접속
$ redis-cli -p 63790
명령어
bf.madd
$ bf.madd fruits apple kiwi
1) (integer) 1
2) (integer) 1- bf.madd [key] [element] 문법
- 저장
bf.exists
$ bf.exists fruits apple
(integer) 1
$ bf.exists fruits lemon
(integer) 0
$ bf.exists fruits banana
(integer) 0- bf.exists [key] [element]
- 존재 여부 확인
false positive때문에 실제로 없는데 집합 안에 있다고 판단할 수 있음
참고
Real-world! Using Redis Course | qu3vipon - Inflearn
qu3vipon | This is a Redis course that you can learn and use right away!: No more tutorial level lectures 🙅♂️ This is a Redis course that can be appl
www.inflearn.com
'데이터베이스 > 0 + Redis' 카테고리의 다른 글
| [Redis] 사용시 주의사항 (0) | 2025.02.03 |
|---|---|
| [Redis] 데이터 타입 활용 (0) | 2025.02.02 |
| [Redis] 특수 명령어 (1) | 2025.01.28 |