
페이징 쿼리?
- 데이터 전체를 조회하지 않고, 원하는 데이터만 전체 데이터에서 부분적으로 나눠서 데이터를 조회 및 처리하는 방법
- DB 및 Application Server의 Resource(CPU, Memory, Netwrok…) 사용 효율이 증가!
- Application 단의 처리 시간이 단축되는 효과!
limit, offset을 사용하는 경우 오히려 DBMS 서버에 더 많은 부하를 발생시킨다.
- 일반적으로 DB 서버에서 제공하는 limit, offset 구문을 사용하는 경우가 대다수!
- limit, offset을 사용하는 경우 오히려 DBMS 서버에 더 많은 부하를 발생시킨다.
select * from table limit 500 offset 0;
select * from table limit 500 offset 500;
select * from table limit 500 offset 1000;
....
select * from table limit 500 offset N;
-- 결국 N이 커질 수록 N개만큼 조회한다.- DBMS 에서 지정된 offset 이후 데이터만 바로 가져올 수는 없습니다.
- 무조건 순차적으로 레코드를 읽어서 필요한 부분만 남기고 나머지는 버림…
- 결국 limit, offset 구문을 사용하는 경우 쿼리 실행 횟수가 늘어날수록 점점 읽는 데이터가 많아집니다.(응답시간도 증가)
- 500건씩 N번 조회 시 최종적으로
((1*500) + (2*500) + (3* 500) + … + (N*500))건의 레코드 읽기가 발생 합니다. - limit, offset 을 사용하지 않고 한번에 모두 읽어서 가져가는 것보다 더 많은 데이터를 읽고 처리하게 됩니다….
- 500건씩 N번 조회 시 최종적으로
따라서 limit, offset 구문을 사용하지 않으면서, 데이터를 원하는 만큼만 조회할 수 있는 쿼리를 작성해야 합니다..!
limit, offset 구문을 사용하지 않으면서, 데이터를 원하는 만큼만 조회할 수 있는 쿼리를 작성하기
- 범위 기반 방식
- 데이터 갯수 기반 방식
범위 기반 방식
- 날짜 기간이나 숫자 범위로 나눠서 데이터를 조회하는 방식
- 매 쿼리 실행 시 where 절에서 조회 범위를 직접 지정하는 형태
- 쿼리에서 limit 절이 사용되지 않음!!
- 주로 배치 작업 등에서 테이블의 전체 데이터를 일정한 날짜/숫자 범위로 나눠서 조회할 때 사용
- 쿼리에서 사용되는 조회 조건도 굉장히 단순하고, N번 쿼리를 나누어 실행하더라도 사용하는 쿼리 형태는 동일!
숫자인 id값을 바탕으로 범위를 나눠 데이터 조회(1,000 단위로 조회)
select *
from member
where id > 0 and id <= 1000
날짜 기준으로 나눠서 조회(월 단위로 조회)
select *
from orders
where created_at >= '2024-07-01' and created_at < '2024-08-01'
데이터 갯수 기반 방식(커서 방식)
- 지정된 데이터 건수만큼 결과 데이터를 반환하는 형태로 구현된 방식
- 주로 서비스 단에서 많이 사용하는 방식으로, 쿼리에서 order by, limit 절이 사용
- 처음 쿼리를 실행할 때(1회차)와 그 이후 쿼리를 실행할 때(N회차) 쿼리 형태가 달라짐
- 쿼리의 where 절에서 사용되는 조건 타입에 따라서 N회차 실행 시의 쿼리 형태도 달라짐
데이터 갯수 기반(동등 조건 사용시)
create table orders (
id bigint not null auto_increment,
member_id bigint not null,
... ,
primary key(id),
key ix_member_id (member_id, id)
);
조회 쿼리
-- 1회차
select *
from orders
where member_id = ?
order by id
limit 30;
-- N 회차
select *
from orders
where member_id = ?
and id > {이전 데이터의 마지막 id 값} -- 식별자 컬럼이 포함
order by id
limit 30;✅ order by 절에는 각각의 데이터를 식별할 수 있는 식별자 컬럼(pk 같은 컬럼)이 반드시 포함되어야 합니다.!
데이터 갯수 기반(범위 조건 사용 시)
create table orders (
id bigint not null auto_increment,
member_id bigint not null,
... ,
primary key(id),
key ix_created_at_id (created_at, id) -- **(created_at, id) 인덱스**
);
1회차 조회 쿼리
select *
from orders
where created_at >= '{시작 날짜}'
and created_at < '{종료 날짜}'
order by created_at, id -- 범위 조건 컬럼인 created_at 포함
limit 30;order by 절에 범위 조건 컬럼인 created_at이 포함되어 있습니다.
왜 order by 절에 created_at이 포함되어야 할까? 🤔
그 이유는 바로 쿼리 성능 향상 효과가 있기 때문입니다!!
created_at 컬럼을 선두에 명시하면, (created_at, id) 인덱스를 사용해서 정렬 작업 없이 원하는 건수만큼 순차적으로 데이터를 읽을 수 있으므로 처리 효율이 향상하게 됩니다!
만약, id컬럼만 명시하는 경우, 조건을 만족하는 데이터를 모두 읽은 후에 id로 정렬한 다음 지정된 건수만큼 반환하게 됩니다.
N회차 조회 쿼리
select *
from ordres
where created_at >= '2024-07-01 00:00:00'
and created_at < '2024-07-02 00:00:00:'
and id > {이전 데이터의 마지막 아이디} -- 식별자 사용
order by created_at, id
limit 5;
✅ 데이터 갯수 기반 방식(범위 조건 사용시)에서 id(식별자)의 순서가 동일하지 않은 경우는…?!
위와 같이 식별자만을 이용해서 쿼리를 작성하면 데이터 누락이 발생할 수 있습니다.
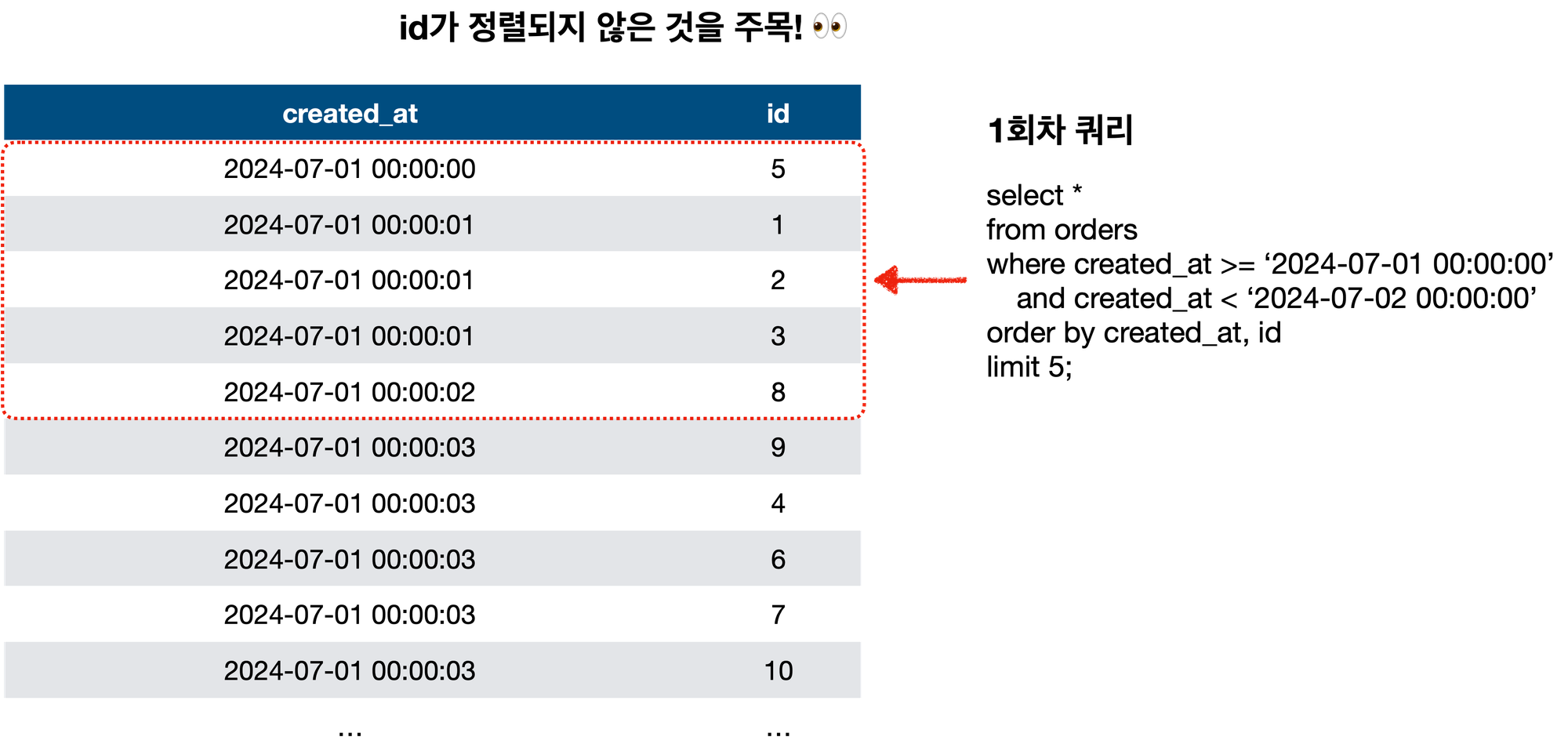
아래 쿼리를 사용하게 되면, 데이터 누락이 발생하게 됩니다….
select *
from ordres
where created_at >= '2024-07-01 00:00:00'
and created_at < '2024-07-02 00:00:00:'
and id > 8 -- 식별자 사용
order by created_at, id
limit 5;
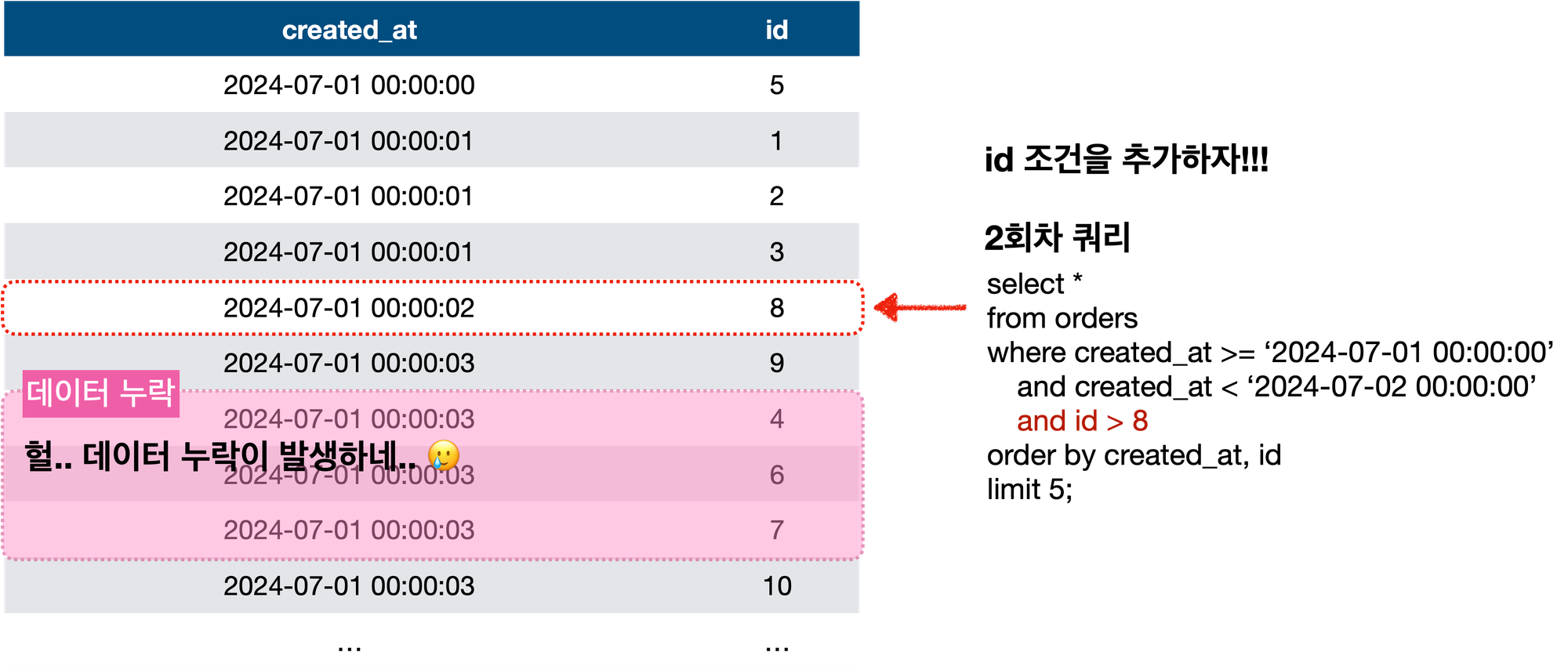
따라서 아래와 같이 쿼리를 작성해야 합니다.
select *
from ordres
where ((created_at >= '2024-07-01 00:00:02' and id > 8)
or (created_at > '2024-07-01 00:00:02'
and created_at < '2024-07-02 00:00:00'))
order by created_at, id
limit 5;

N회차 쿼리를 정리하면 아래와 같습니다.
select *
from ordres
where ((created_at >= '{이전 마지막 데이터의 날짜값}' and id > {이전 마지막 데이터의 id 값})
or (created_at > '{이전 마지막 데이터의 날짜값}'
and created_at < '{종료 날짜}'))
order by created_at, id
limit 5;
정리
- limit, offest 구문은 DB서버 부하를 발생시키므로 사용을 지양
- 페이징 쿼리는 대표적으로 2가지로 구분할 수 있음
- 범위 기반 방식
- 데이터 갯수 기반 방식
- 범위 기반 방식은 단순하게 날짜/숫자 값을 특정 범위로 나눠서 쿼리를 실행하는 형태
- 1회차, N회차 쿼리가 동일!
- 데이터 갯수 기반 방식은 지정한 데이터 갯수만큼만 조회하는 형태
- 1회차, N회차 쿼리가 다름
- 쿼리에 사용되는 조건 타입 또는 경우에 따라서 쿼리의 형태가 달라지기 때문에, 페이징을 적용하고자 하는 쿼리에 알맞은 형태로 쿼리를 작성해야함!
참고
Real MySQL 시즌 1 - Part 1 강의 | 이성욱 - 인프런
이성욱 | MySQL의 핵심적인 기능들을 살펴보고, 실무에 효과적으로 활용하는 방법을 배울 수 있습니다. 또한, 오랫동안 관성적으로 사용하며 무심코 지나쳤던 중요한 부분들을 새롭게 이해하고,
www.inflearn.com
'데이터베이스 > 0 + MySQL' 카테고리의 다른 글
| [MySQL] Stored Function 에서 많이 하는 실수 방지하기 (0) | 2024.08.21 |
|---|---|
| [MySQL] left join 아무생각 없이 사용하고 있는 것은 아니지? (0) | 2024.08.15 |
| [MySQL] count(*) 과 count(distinct) (2) | 2024.07.20 |
| [MySQL] VARCHAR vs TEXT (1) | 2024.07.20 |
| [MySQL] CHAR vs VARCHAR (0) | 2024.07.06 |