[가상 면접 사례로 배우는 대규모 설계 기초] 1. 사용자 수에 따른 규모 확장성

넌 대용량 데이터를 다루지 않으면서 왜 이책을 보는거야? 🤔
최근 면접을 진행하면서 꼭 빠지지 않은 질문이 있었다.
바로 대용량 데이터 처리 대한 질문이었다.
그럴때마다 나는 우물쭈물 어쩔줄 몰라했다…. 😇
대용량 데이터를 처리할 수 있는 환경이 아니었단 말이야! 라고 핑계를 댈 수 있다.
그런데 훌륭한(?) 개발자라면 대용량에 대한 설계를 고려하면서 애플리케이션을 개발해야 한다고 생각한다.
컴퓨터의 존재 목적 자체가
사람이 감당할 수 없는 대량의 데이터(1,000개, 10만개… 1,000만개!!)를
처리하기 위해 등장했다고 생각하기 때문이다.ㅎㅎ
이제 앞으로 1,000건 10,000건 정도가 아닌
데이터가 1천만개라면..? 아니! 1억개라면…?
같은 극단적인 생각을 가지고 고민하며 애플리케이션을 설계하는 습관가지면,
정말로 대용량 데이터를 처리할 수 있는 능력이 생기지 않을까…? ㅎㅎ 😇
그렇지만, 대규모 서비스를 운영하는 회사에서 근무하지 않는 이상 이러한 문제를 만나기는 어렵기 때문에, 간접으로라도 배우려고 대용량 데이터 처리와 관련된 책을 읽어보려고 한다.
단일 서버
웹 애플리케이션을 설계하면 처음에 떠오르는 구조는 일반적으로 아래와 같이 단일 서버일 것 입니다.
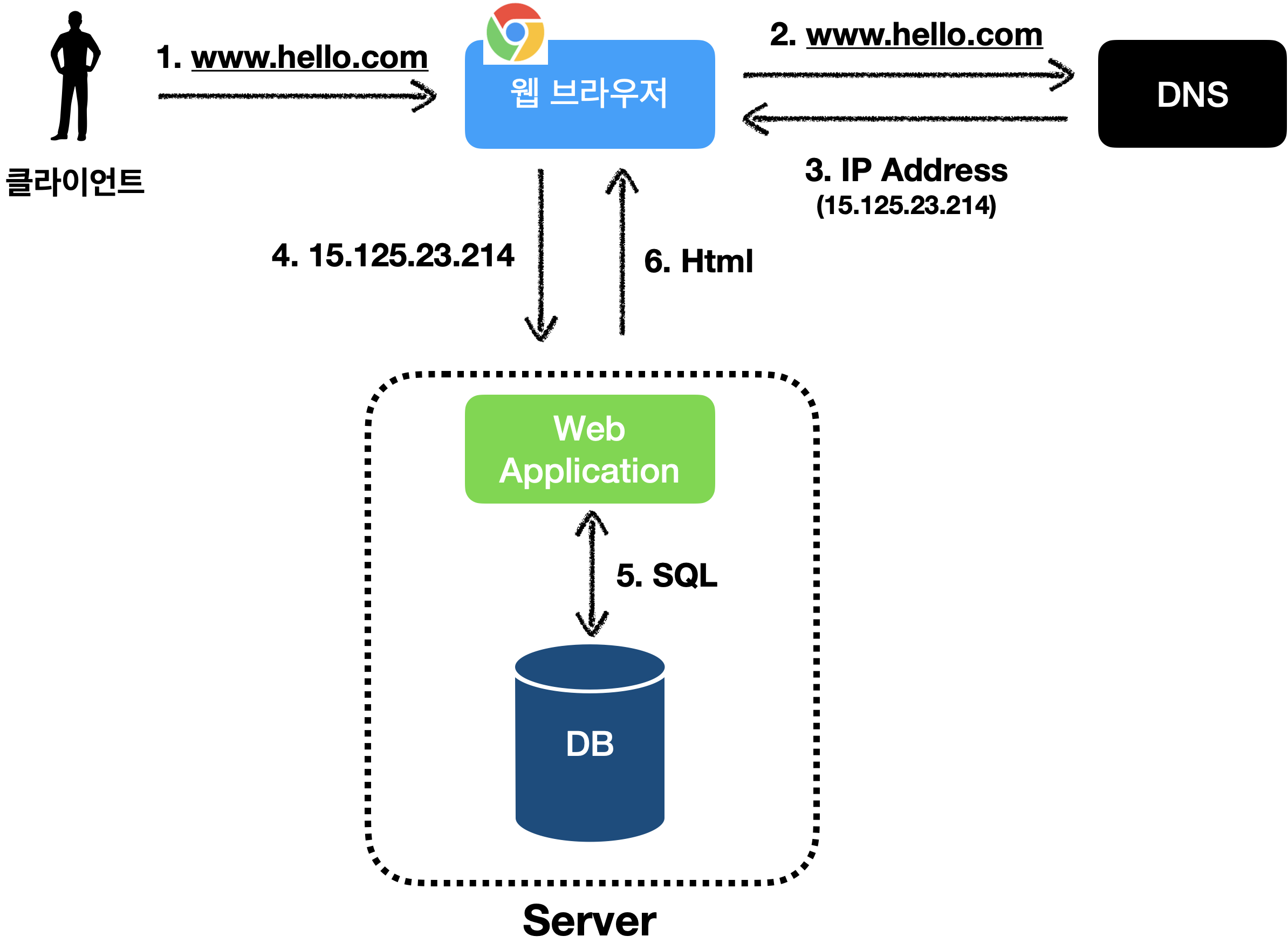

흐름
1. 클라이언트가 브라우저를 통해 도메인 이름을 입력
2. 도메인 이름이 DNS를 통해 IP 주소로 변환
3. IP 주소로 Web Server에 요청
4. Web Server는 알맞은 응답 제공
단일 서버의 문제점은 무엇일까?
단일 서버의 문제점은 무엇일까?
먼저 장점부터 알아보자.
장점은 단순한 구조에 있다.
빠르고 쉽게 기능을 구현할 수 있다.
하지만, 이러한 장점은 한 순간에 무너질 수 있다.
바로 서버에 장애가 발생하면 아무것도 할 수 없다는 것이다.
만약 사용자(👥)가 늘어나서 장애가 발생했다고 가정해봅시다.
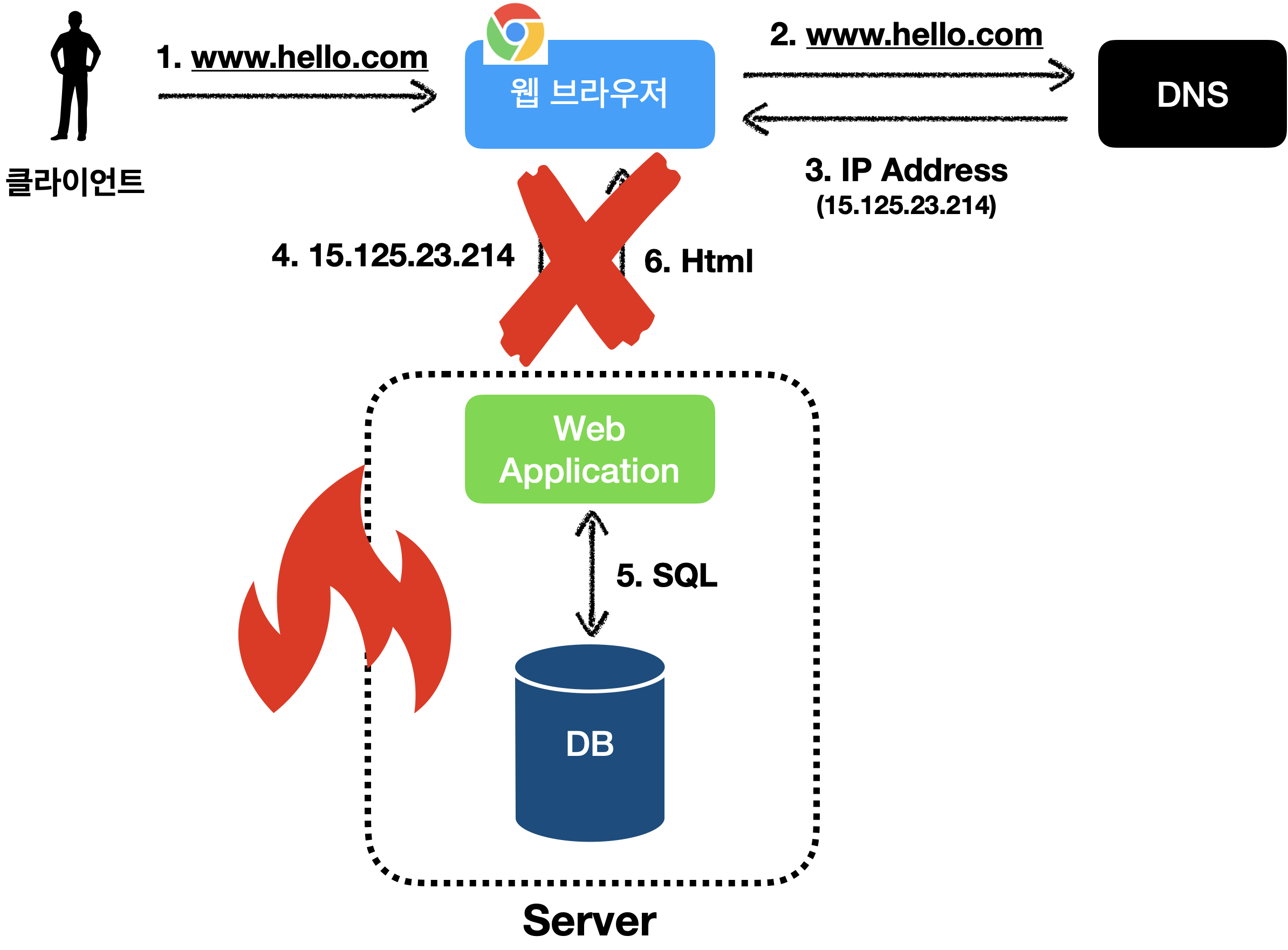

이처럼 한 곳에 웹 애플리케이션과 데이터베이스가 존재하기 때문에
서버에 문제가 발생하면, 아무것도 할 수 없습니다…
우리는 서버 하나로는 충분하지 않다는 것을 알게 되었습니다…
그러면… 여러 서버를 두어야한다는 의미인데,,,,,,
하나는 웹 트래픽 처리용도로 다른 하나는 데이터베이스용으로 서버를 분리를 해보자!
참고
브라우저와 DNS는 우리가 제어할 수 없기 때문에 장애가 발생하지 않는다고 가정했습니다.
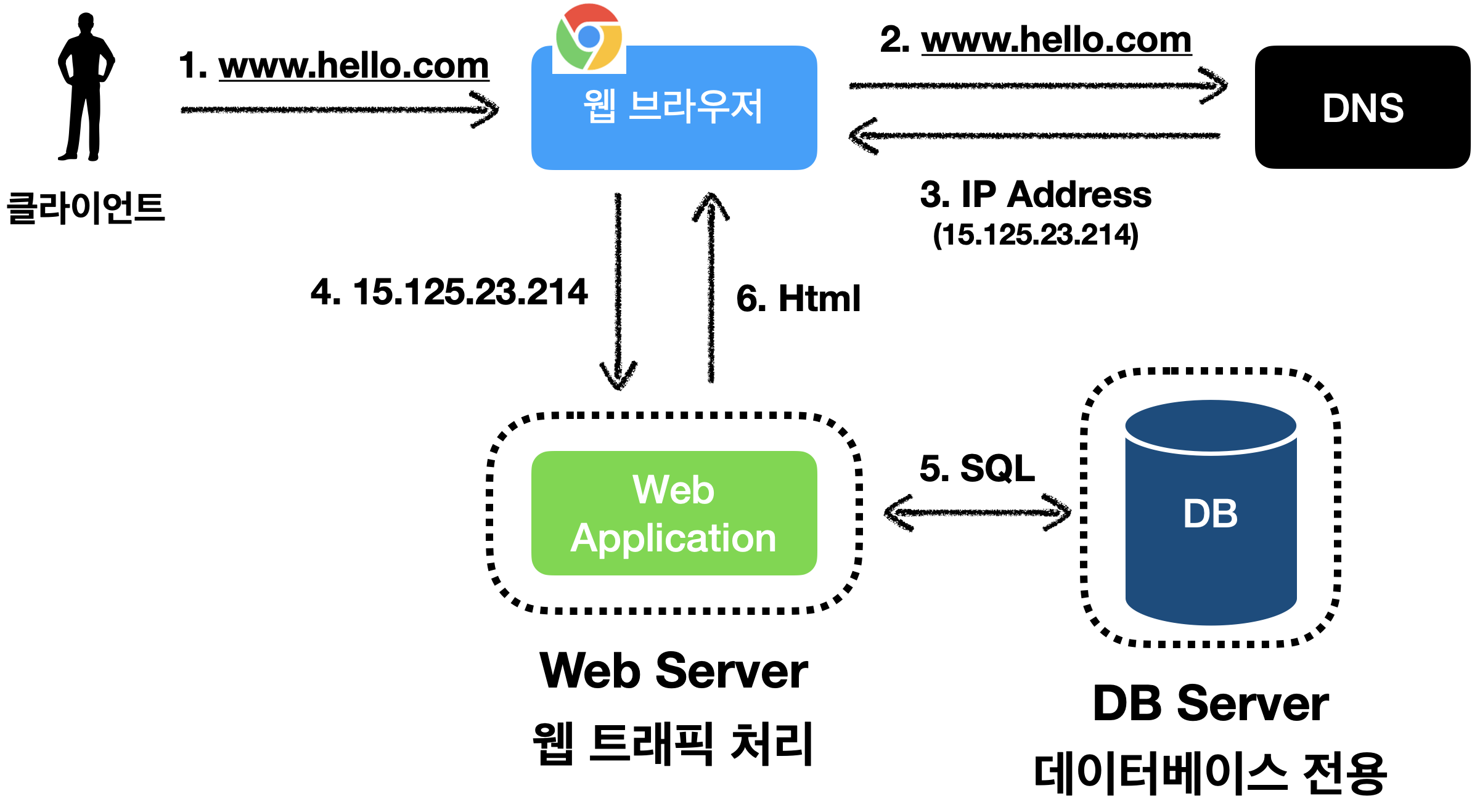
웹 트래픽 처리 서버, 데이터베이스 서버로 분리
서버를 분리하자!
- 웹 트래픽 처리 서버
- 데이터베이스 서버

데이터베이스 장애 상황
서버를 분리한 덕분에 데이터베이스에 장애가 발생하면 에러 페이지를 응답으로 줄 수 있습니다.
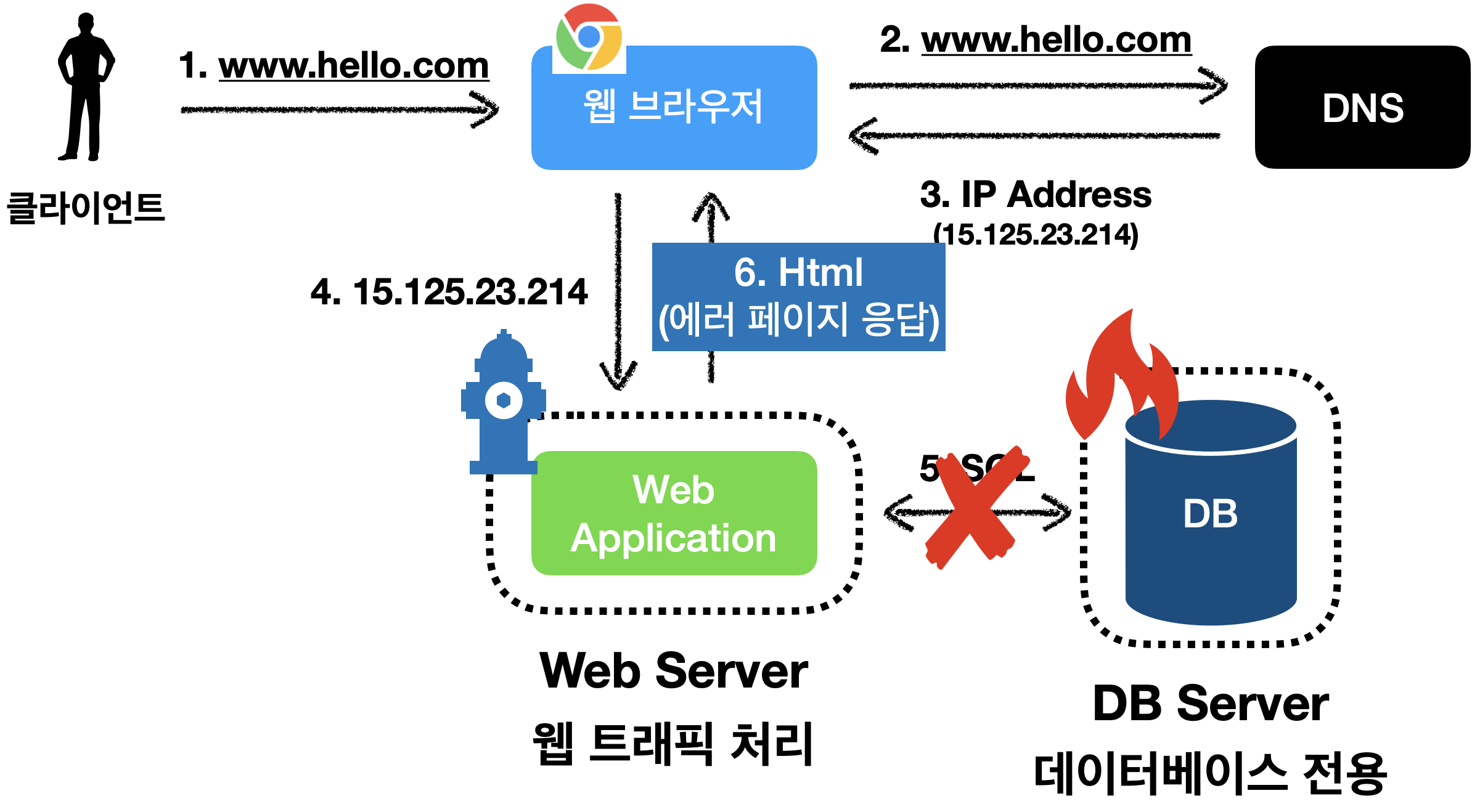

그런데 에러페이지는 정상적인 서비스를 제공하는 것이 아닙니다.
참고
비-관계형 데이터베이스가 필요한 경우
대부분 개발자들에게는 관계형 데이터베이스가 익숙할 것 입니다.
하지만, 구축하는 시스템에 따라 다른 종류의 데이터베이스를 고려해야 할 수도 있습니다.
대표적으로 아래의 경우 비-관계형 데이터베이스를 고려해볼만 합니다.
- 아주 낮은 응답 지연시간이 요구
- 다루는 데이터가 비정형(관계형이 아님)
- 데이터를 직렬화하거나 역직렬화할 수 있기만 하면 됨
- 아주 많은 양의 데이터를 저장할 필요가 있음
🧨 장애가 발생해도 정상적으로 서비스를 운영하고 싶습니다!
바로 서버를 확장하면 됩니다!
우리는 서버를 분리했기 때문에 각각 독립적으로 쉽게 확장할 수 있습니다.
서버 확장이 정확하게 무엇인지 알아보도록 합시다!
서버 확장(수직적 규모 확장 VS 수평적 규모 확장)
서버 확장은 크게 2가지 방법이 존재합니다.
- 수직적 규모 확장
- 수평적 규모 확장
수직적 규모 확장(scale-up)
수직적 규모 확장은 서버에 더 고사양 자원을 추가하는 행위를 의미합니다.
흔히 우리가 PC를 업그레이드하는 방식 입니다.^^
- e.g) MacBook Air(M1) -> MacBook Pro(M2 PRO)
수직적 규모 확장의 장점은 바로 단순함에 있습니다.
그냥 서버에 고사양 자원을 추가하면 되는 것 입니다.
그런데 이러한 방법은 심각한 단점이 존재합니다… 🥲
단점
- 수직적 규모 확장에는 한계가 반드시 존재
- 무한으로 자원을 늘릴 수 없기 때문
- 장애에 대한 자동복구(
failover) 방안이나 다중화(redundancy)방안을 제시하지 않음- 서버에 장애가 발생하면 웹사이트는 완전히 중단
따라서 대규모 애플리케이션을 지원하는 데는 수평적 규모 확장법(scale-out)이 더 적절합니다.^^
수평적 규모 확장(scale-out)
수평적 규모 확장은 서버를 추가하여 성능을 개선하는 행위를 의미합니다.
PC를 여러대 구매하여 작업을 분산하는 것 입니다.
로드밸런서
앞선 설계에서 우리는 사용자는 곧장 웹 서버에 연결됩니다.
이때 사용자가 더 많아져서 웹 서버가 다운(🏳️)되면 더 이상 사이트에 접속할 수 없습니다.
엇! 우리는 수평적 규모 확장을 따르기로 했기 때문에 서버를 여러대 추가하면 되는 거 아닌가요?!
맞습니다!!
……..
그런데 서버를 추가 했는데…. 어느 서버에 요청(작업을 할당)을 줘야할까요? 🤔
이런 문제를 해결하는데 로드밸런서를 사용하는 것이 최선입니다.!
로드밸런서는 웹 서버들에게 트래픽을 고르게 분산하는 역할을 합니다.
- e.g) AWS의 Elastic Load Balancing
로드밸런서 추가
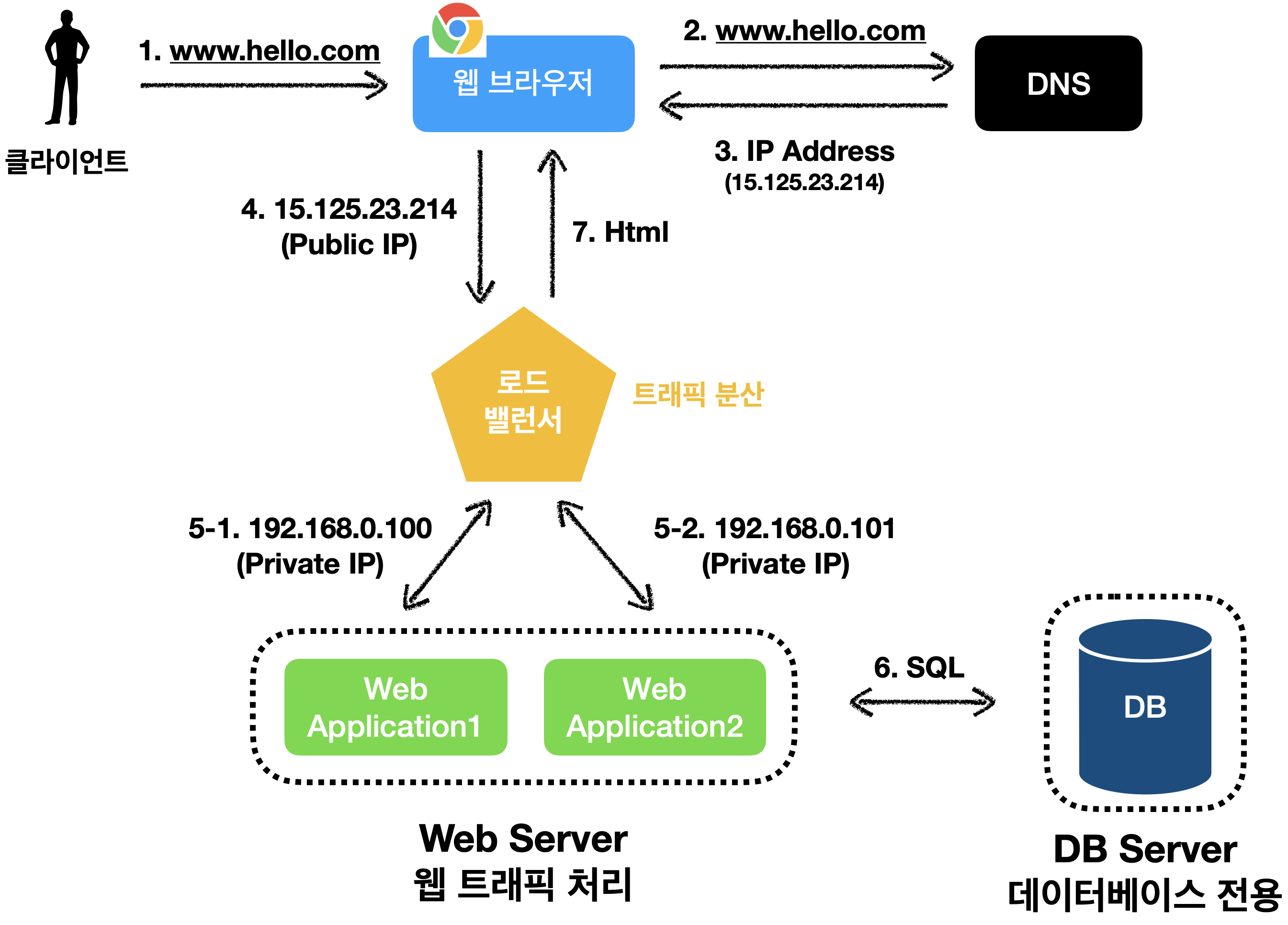

사용자는 로드밸런서의 공개 IP 주소(Public IP)로 접속합니다.
따라서 웹 서버는 클라이언트의 접속을 직접 처리하지 않습니다.
추가로 서버 간 통신에는 사설 IP 주소(Private IP)가 이용 됩니다.
웹사이트로 유입되는 트래픽이 가파르게 증가하면 2대의 서버로 트래픽을 감당할 수 없는 시점이 오게되는데,
로드 밸런서 덕분에 유연하게 대처할 수 있습니다.
웹 계층에 더 많은 서버를 추가하면 되기 때문입니다.! 👍
참고
사설 IP는 동일한 네트워크에 속한 서버 사이의 통신에만 사용할 수 있는 IP 주소로, 인터넷을 통해 접근할 수 없습니다.
no failover 해결
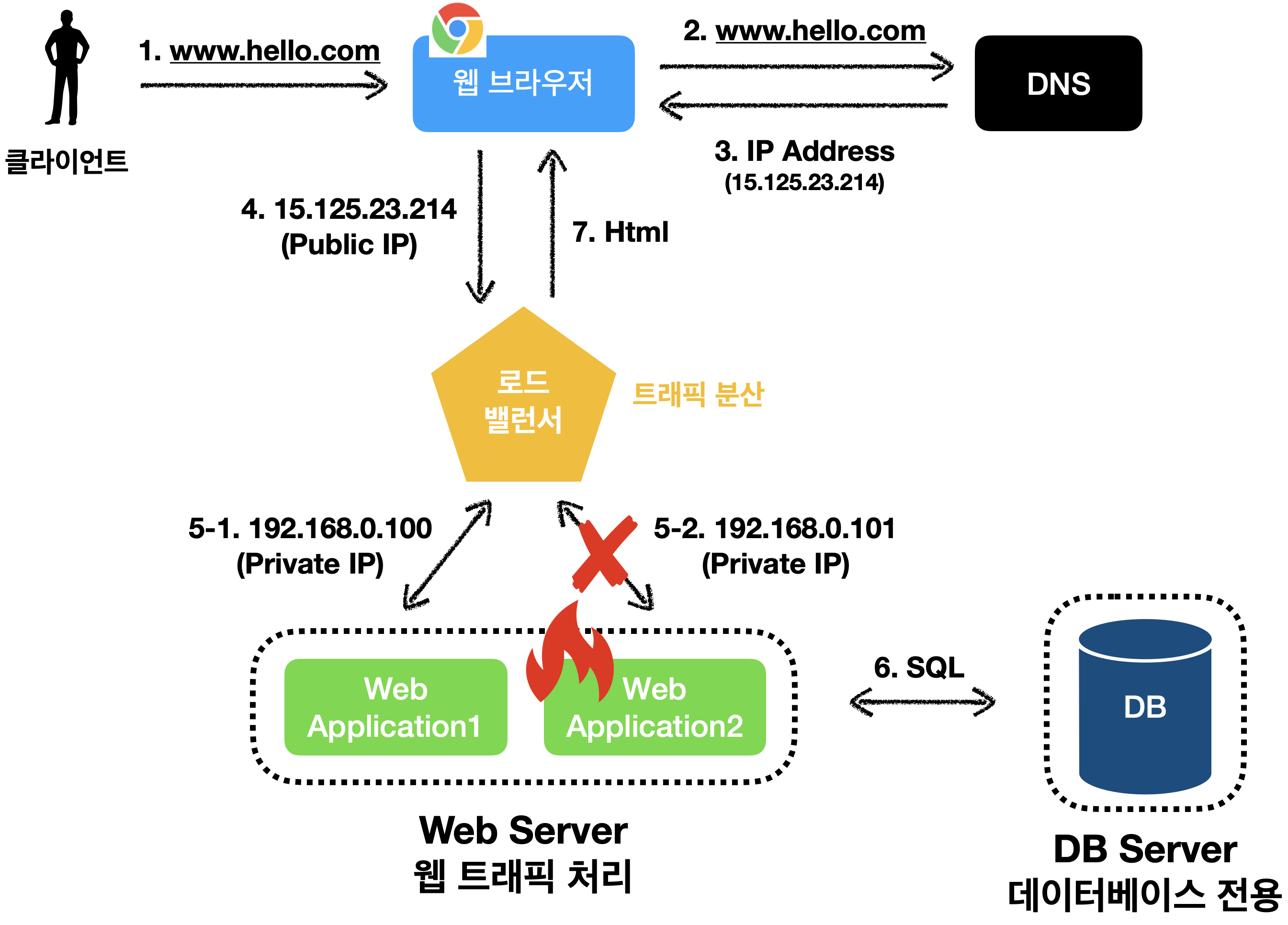

이처럼 스케일 아웃을 통해 하나의 웹 서버를 추가하게 되면,
장애를 자동 복구하지 못하는 문제(no faileover)를 해결할 수 있습니다.
WebApplication2가 다운되면 모든 트래픽을 로드밸런서가 WebApplication1로 전송합니다.
따라서 웹 서비스 전체가 다운되는 일을 방지 합니다.
음.. 그러면 여기서 드는 의문이 있을 것 입니다.
이제 웹 계층은 어느정도 해결된 것 같은데….
데이터 계층은 어떻게 해야하는 걸까? 🤔
데이터베이스 서버 1대일 뿐이고, 장애의 자동복구나 다중화를 지원하는 구성이 아닌데..!
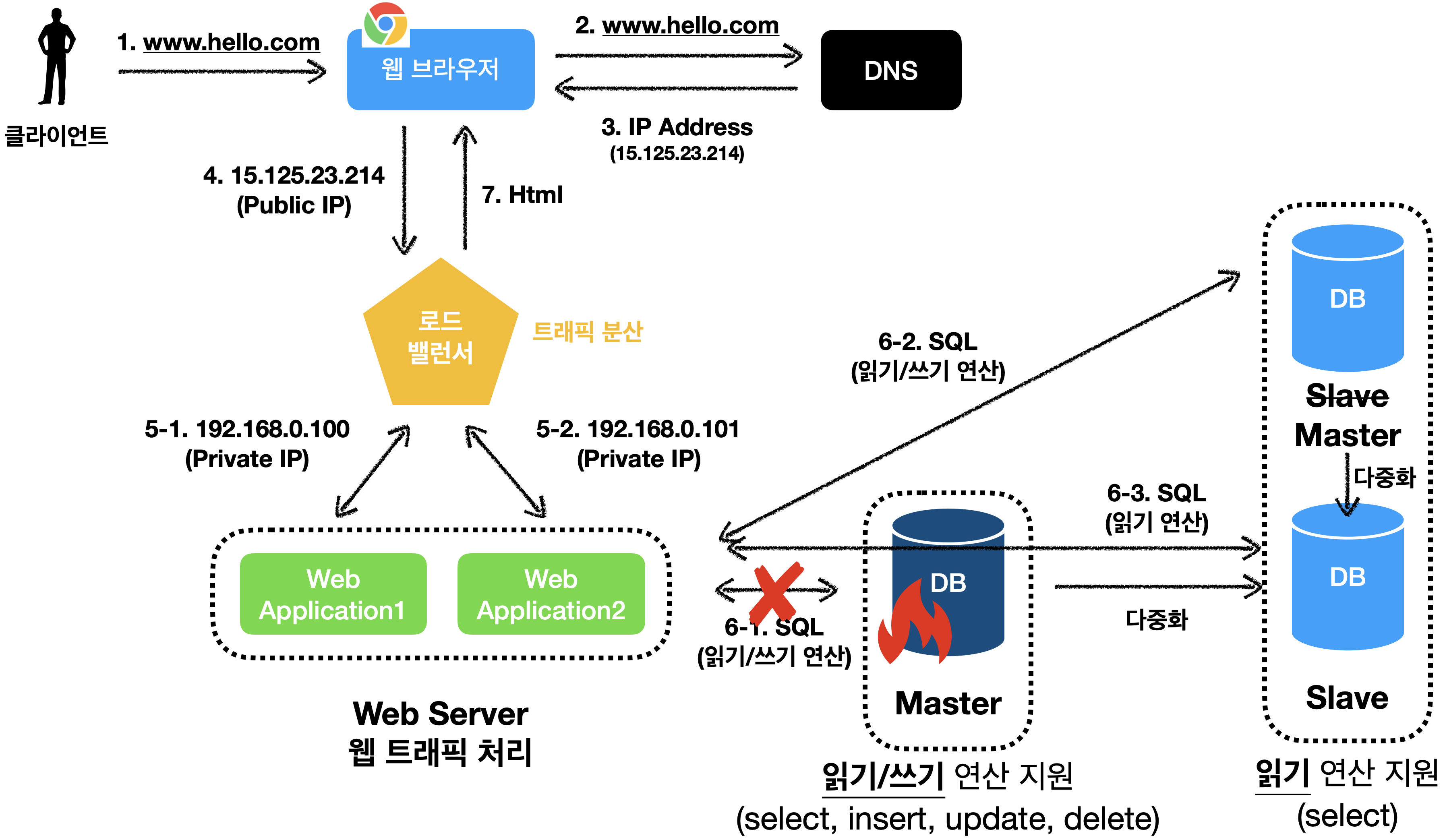
데이터베이스 다중화
데이터베이스는 이러한 문제를 해결하기 위해 보편적으로 데이터베이스 다중화라는 기술을 지원합니다.
데이터베이스 다중화는 일반적으로 아래와 같은 방식을 사용합니다.
서버 사이에 master <--> slave 관계를 설정하고 데이터 원본은 master에, 사본은 slave에 저장하는 방식 입니다.

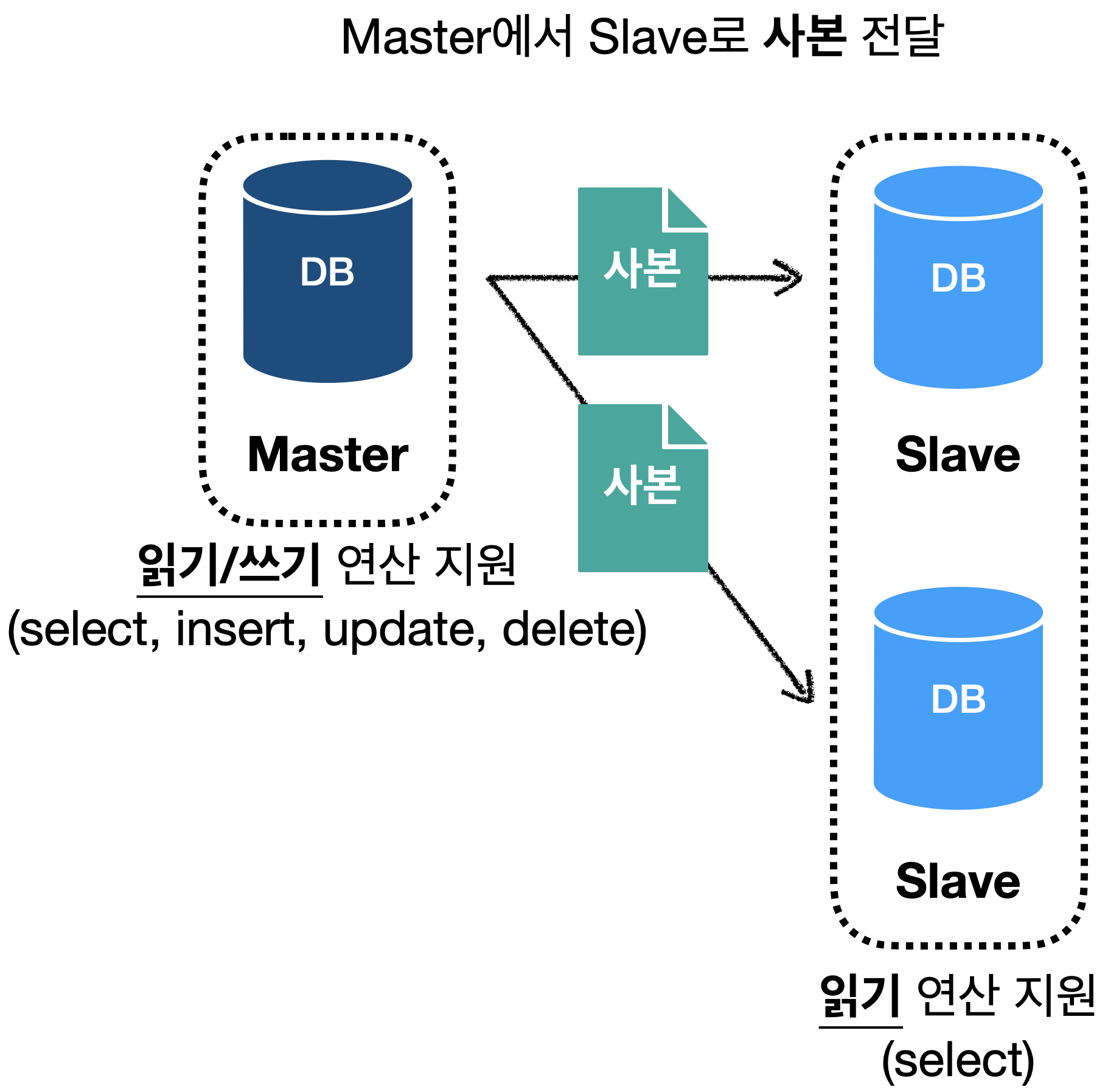
쓰기 연산은 master에만 지원하고, slave는 읽기 연산만 지원합니다.
(slave는 master로 사본을 전달 받습니다.)
대부분의 애플리케이션은 읽기 연산의 비중이 쓰기 연산에 비해서 압도적으로 높습니다.
따라서 일반적으로 slave 데이터베이스 수가 master 데이터베이스 보다 많습니다.
(master도 읽기 연산을 지원하지만, slave에 문제가 발생하지 않는 이상 대부분의 읽기 연산은 slave와 통신 합니다.)
데이터베이스 다중화


이렇게 데이터베이스를 다중화하면 아래와 같은 이점이 있습니다.
- 성능! 성능!! 성능!!!
master <--> slave다중화 모델에서 모든 데이터 변경은master데이터베이스 서버로만 전달되는 반면에, 읽기 연산은slave데이터베이스들로 분산됩니다. 이는 병렬로 처리될 수 있는 SQL수가 늘어나기 때문에 자연스럽게 서능이 좋아집니다.
- 안정성(reliability)
- 서버를 분산하면 자연 재해 등의 이유로 데이터베이스 일부가 파괴되어도 데이터는 보존 됩니다. 데이터베이스 서버를 지역적으로 여러 장소에 다중화할 수 있기 때문입니다.
- 가용성(availability)
- 데이터를 여러 지역에 복제한 덕분에, 하나의 데이터 서버에 장애가 발생하더라도, 다른 서버에 있는 데이터를 가져와 계속 서비스할 수 있습니다.
slave가 다운되는 경우
읽기 연산은 나머지 데이터베이스 서버들로 분산 될 것 입니다.
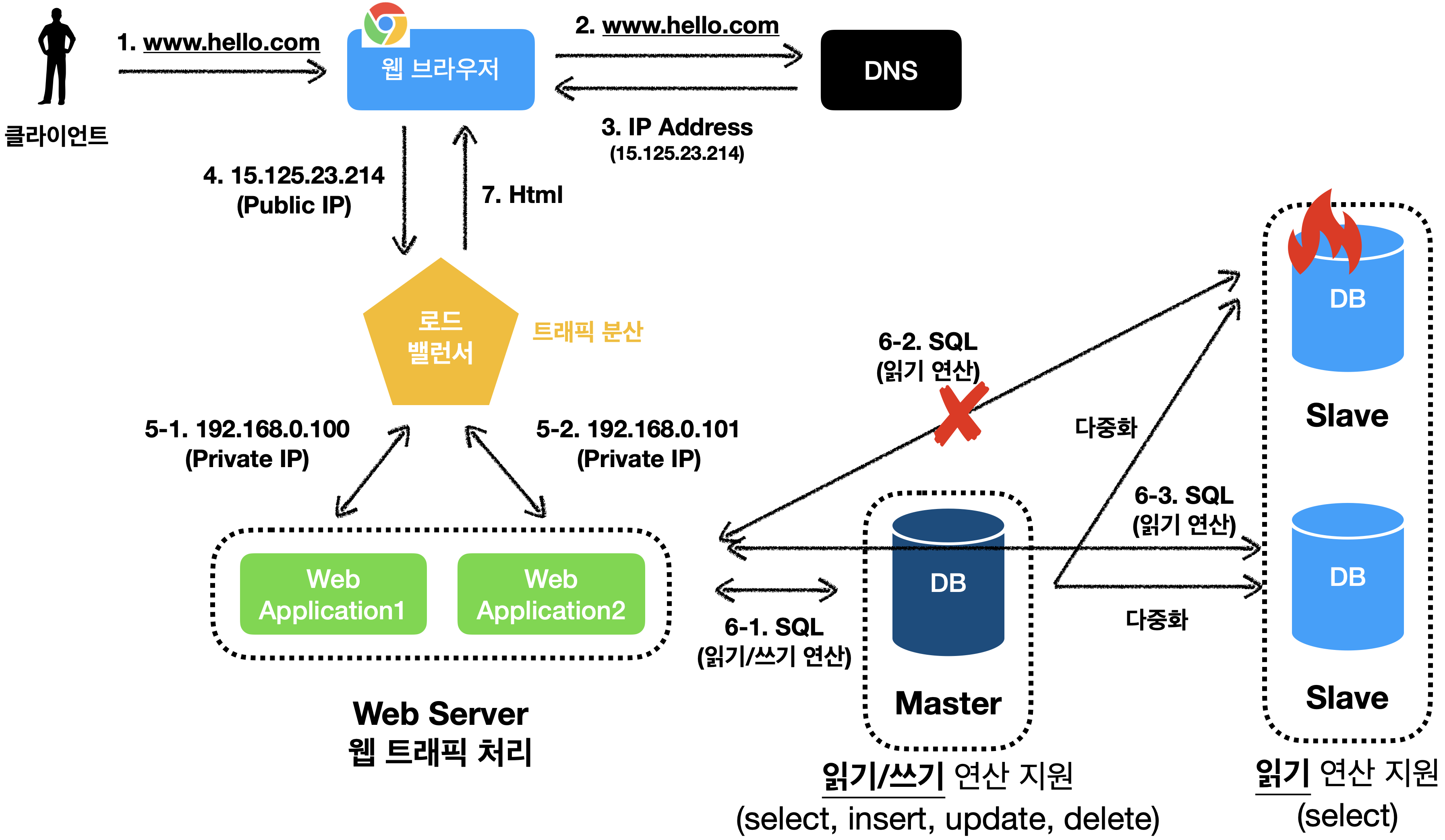

master가 다운되는 경우Master 데이터베이스가 다운되면, slave 데이터베이스 중 하나가 새로운 master 데이터베이스가 될것 입니다.

다만, slave 데이터베이스에 보관된 데이터가 최신 상태가 아닐 수도 있기 때문에, 이런 경우 recovery script를 사용해서 추가해야 합니다.
추가로, 다중 마스터(multi-masters) 또는 원형 다중화(circular replication) 방식을 도입하면 이런 상황을 해결하는데 도움이 될수 도 있습니다.
slave가 1개인 경우에 slave가 다운된 경우
읽기 연산은 한시적으로 모두 master 데이터베이스로 전달 될 것 입니다.
Yeah~!!! 👍
이제 웹 계층과 데이터 계층을 충분히 분리하게 되었습니다.!!!
마지막으로 우리 응답시간을 개선해 볼까요? 🤗
응답시간 개선
응답 시간을 개선하기 위한 방법에는 무엇이 있을까요?
음…
사용자의 모든 요청마다 webApplication과 DB를 거칠 필요가 있을까요…?
정답은
굳이 그럴 필요 없다. 는 것 입니다!
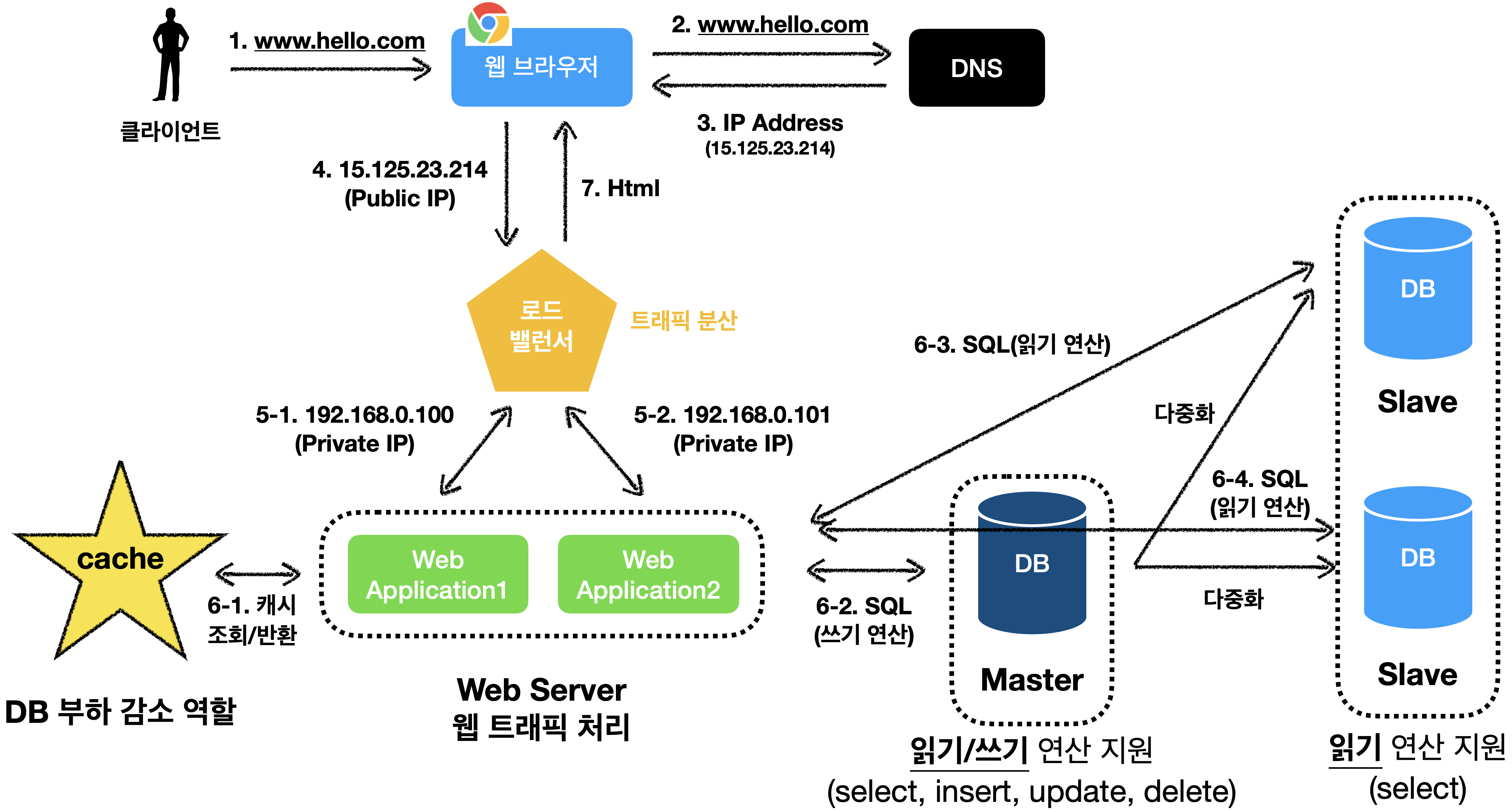
캐시(cache)를 사용하고, 정적 콘텐츠를 전송 네트워크(Content Delivery Network: CDN)로 옮기면 됩니다!!!
캐시(cache)
캐시는 저장소 입니다.!
캐시는 아주 값 비싼 연산 결과 또는 자주 참조죄는 데이터를 메모리 안에 두고, 요청이 빨리 처리될 수 있도록 하는 저장소 입니다.
일반적으로 애플리케이션 성능은 데이터베이스를 얼마나 자주 호출하느냐에 크게 좌우되는데, 캐시는 이러한 문제를 완화할 수 있습니다.
캐시 계층(cache tier)


캐시 계층은 데이터가 잠시 보관되는 곳으로 데이터베이스보다 훨씬 빠릅니다.
웹 서버와 데이터베이스 사이에 캐시를 두면 성능이 개선될 뿐 아니라, 데이터베이스의 부하를 줄일 수 있고, 캐시 계층의 규모를 독립적으로 확장시키는 것도 가능합니다.
읽기 주도형 캐시 전략(read-through caching strategy)


이렇게 보면 캐시를 사용하면 무조건 좋은것 같습니다.
하지만, 모든 기술이 그렇듯 고려해야할 사항들이 있습니다.
핵심은 캐시를 이용하면 데이터베이스의 부하를 줄인다.! 이것 1개만 기억하셔도 됩니다.👍
캐시 도입시 고려사항
- 데이터 참조? 데이터 갱신/생성?
- 캐시는 데이터 갱신은 자주 발생하지 않지만, 참조는 자주 발생하는 상황이라면 고려해볼 만합니다.
- 어떤 데이터를 캐시에 두지?
- 캐시는 휘발성 메모리이기 때문에, 영속적으로 보관해야할 데이터를 캐시에 저장하는 것은 바람직 하지 않습니다.
- 캐시에 보관된 데이터 만료정책?
- 필요한 데이터를 캐시에 무한정으로 보관하게 된다면, 메모리 부족 현상이 발생할 수 있습니다. 따라서 적절한 데이터 만료정책을 고려해야 합니다.
- 만료기간이 너무 짧으면, 데이터베이스를 자주 참조하게 될것이고, 만료기간이 너무 길면, 원본과 차이가 날 가능성이 높아지게 됩니다.
- 어떻게 데이터 일관성(
consistency)을 유지할것 인가?- 일관성은 데이터 저장소의 원본과 캐시 내의 사본이 같은지 여부 입니다.
- 원본을 갱신하는 연산과 캐시를 갱신하는 연산이 단일 트랜잭션으로 처리되지 않는 경우, 일관성은 깨질 수 있습니다.
- 일반적으로 여러 지역에 걸쳐 시스템을 확장해 나가는 경우 캐시와 저장소 사이의 일관성을 유지하는 것은 어려운 문제..(Scaling Memcache at Facebook - Meta Research | Meta Research 논문 참고)
- 장애 대처
- 만약 캐시 서버를 1대만 사용할 경우 캐시 서버에 장애가 발생하는 경우 단일 장애 지점(
Single Point of Failure: SPOF)가 될 수 있습니다. - 캐시 서버를 여러 지역에 걸쳐 분산시키는 것을 고려해야 한다.
- 만약 캐시 서버를 1대만 사용할 경우 캐시 서버에 장애가 발생하는 경우 단일 장애 지점(
- 캐시 메모리의 크기
- 캐시 메모리가 너무 작으면 접근 패턴에 따라서 데이터가 너무 자주 캐시에 밀려나서(
eviction) 캐시 성능이 떨어지게 됩니다. 이를 막을 수 있는 유일한 방법은 캐시 메모리를 과할당(overprovision) 하는 것 입니다. 이렇게 하면, 캐시에 보관될 데이터가 갑자기 늘어났을 때 생길 문제도 방지할 수 있게 됩니다.^^
- 캐시 메모리가 너무 작으면 접근 패턴에 따라서 데이터가 너무 자주 캐시에 밀려나서(
- 데이터 방출(eviction) 정책
- 캐시 메모리가 가득 차면, 추가로 캐시 데이터를 넣을때 기존 데이터를 삭제해야 합니다. 이것을 캐시 데이터 방출 정책이라고 하는데, 가장 많이 사용하는 정책은
LRU(Least Recently Used: 가장 오랫동안 사용하지 않은 데이터를 삭제하는 정책)입니다. 그외로FIFO,LFU등이 있습니다.
- 캐시 메모리가 가득 차면, 추가로 캐시 데이터를 넣을때 기존 데이터를 삭제해야 합니다. 이것을 캐시 데이터 방출 정책이라고 하는데, 가장 많이 사용하는 정책은
캐시를 추가한 설계
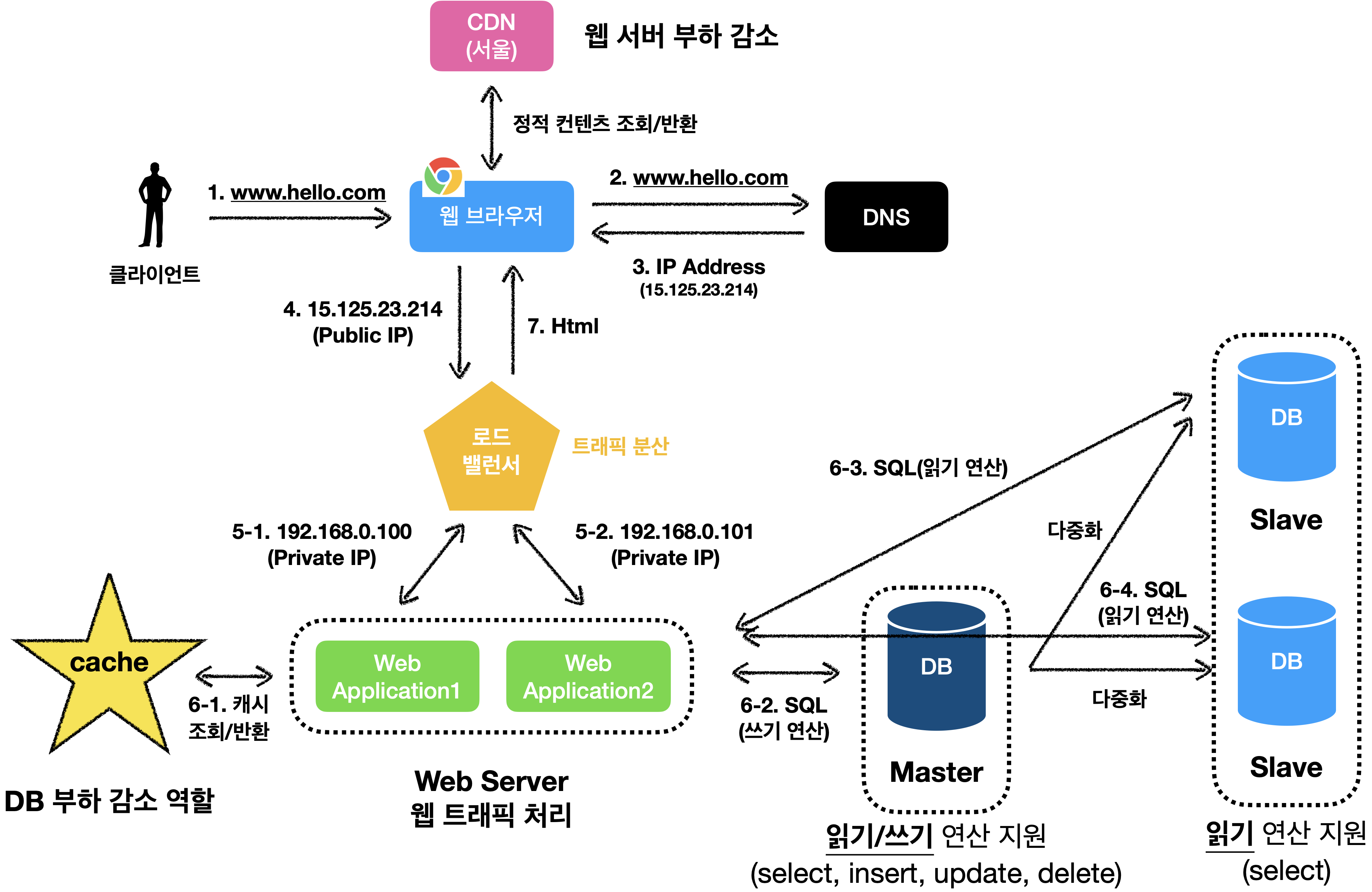
콘텐츠 전송 네트워크(Content Delivery Network: CDN)
CDN은 정적 콘텐츠를 전송하는 데 사용하는, 지리적으로 분산된 서버의 네트워크 입니다.
CDN을 통해 .js, .css, 이미지, 비디오 파일등을 캐시할 수 있습니다.
*여기에서는 정적 컨텐츠를 캐시하는 방법만 소개하겠습니다.
CDN을 사용하면, 사용자에서 가장 가까운 CDN 서버가 정적 컨텐츠를 전달하게 됩니다.
여기에서 CDN은 지리적으로 분산된 서버의 네트워크 이기 때문에,
사용자가 CDN으로부터 멀먼 멀수록 웹사이트는 천천히 로드될 것 입니다.!
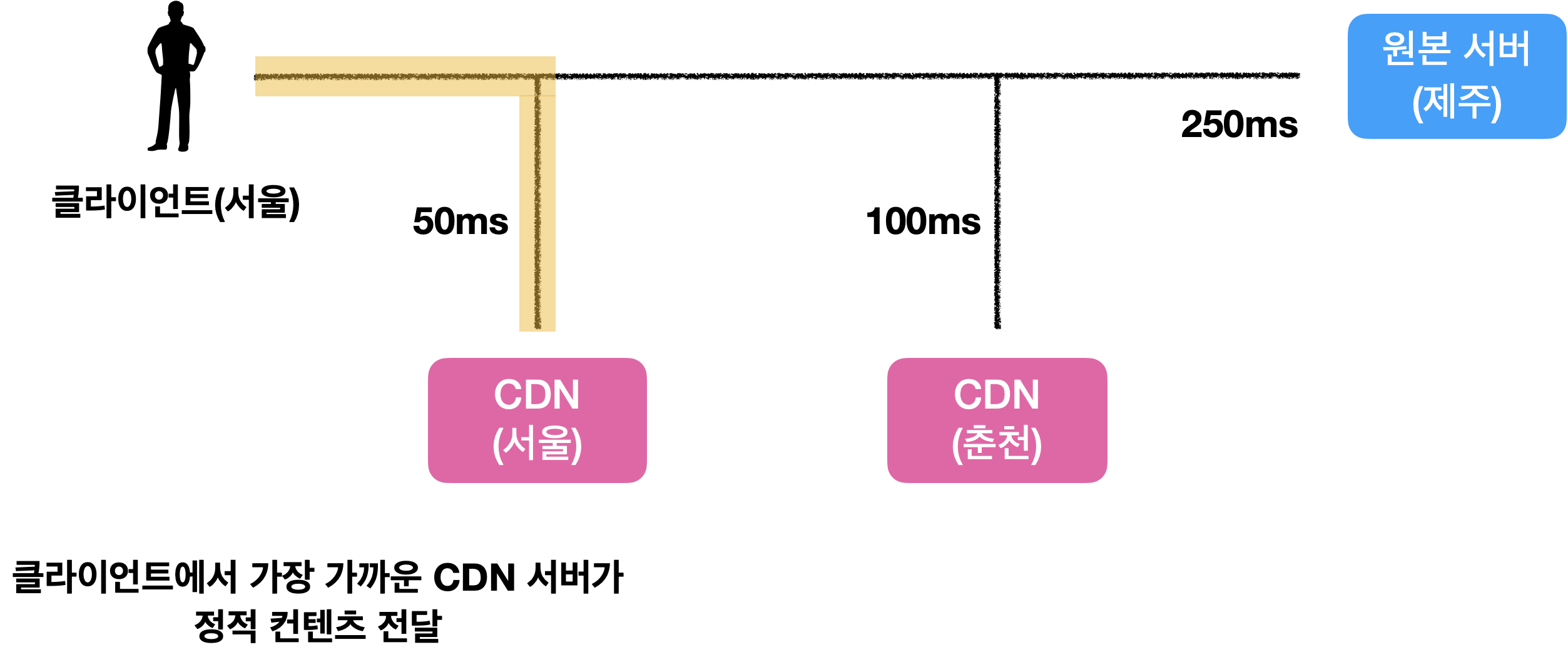
CDN 동작 구조
CDN 흐름
- 사용자가
CDN사업자에서 제공한URL을 이용하여.js에 접근 CDN서버의 캐시에 해당.js파일이 없는 경우, 서버는 원본(origin) 서버에 요청하여 파일을 가져옴- 원본 서버가 파일을
CDN서버에 반환- 응답의
HTTP헤더에는 해당 파일이 얼마나 오랫동안 캐시될 수 있는 표현하는TTL(Time-To-Live)값이 들어 있음
- 응답의
CDN서버는.js파일을 캐시하고 사용자에게 반환TTL에 명시되어 있는 시간까지 보관
CDN에 요청데이터가 있을 경우


사용자가 hello.js를 URL을 이용하여 접근합니다.
이때 URL은 CDN 서비스 사업자가 제공한 것입니다.
- e.g)
https://mysite.akamai.com/hello.js
CDN에 요청데이터가 없을 경우


결과적으로, 사용자에게 TTL에 명시되어있는 시간까지 CDN을 통해서 정적 콘텐츠를 반환하기 때문에 우리가 개발한 원본(origin) 서버를 거치지 않습니다.!
따라서 응답시간을 줄일 수 있게 되었습니다.
이제 CDN을 사용할 때 고려사항에 대해서 알아봅시다.
CDN 사용시 고려사항
- 비용
CDN은 제3 사업자에 의해 운영되기 때문에,CDN사업자에게 비용을 지불해야 합니다.- 자주 사용하지 않는 컨텐츠를 캐싱하는 것은 비용적으로 불리하기 때문에
CDN에서 제외하는 것을 고려해야 합니다.
- 적절한 만료 기간 설정
- 시의성(
time-sensitive)컨텐츠의 경우 만료 시점을 잘 설정해야 합니다. - 너무 짧으면 원본서버에 빈번하게 접속해야하고, 너무 길면 콘텐츠의 신선도가 떨어질 것 입니다.
- 시의성(
- CDN 장애시 대처 방안
- CDN에 너무 의존하여 애플리케이션을 설계하면 안됩니다. CDN 자체가 다운되었을 경우에는 어떻게 동작해야 하는가?에 대해서 고려하여 CDN 서버가 다운되었을 경우, 원본서버를 통해서 컨텐츠에 접근할 수 있도록 설계해야 합니다.
- 컨텐츠 제거(invalidation)
- 아직 만료되지 않은 컨텐츠라 하더라도
CDN에서 컨텐츠를 제거(무효화)하려면 어떻게 해야할까요?CDN사업자에서 제공하는API를 사용하여 제거하는 방법 사용- 컨텐츠의 다른 버전을 서비스하도록 오브젝트 버저닝(
object versioning)을 이용합니다.- e.g)
image.png?v1.0,image.png?v2.0
- e.g)
- 아직 만료되지 않은 컨텐츠라 하더라도
CDN을 적용한 설계
무상태(stateless)을 유지하면서 웹 계층 확장하기
캐시와 CDN까지 적용한 설계를 보니 흐뭇해지고, 어떤 트래픽에도 끄떡없을 것 같습니다. 😆
그런데, 지금까지의 설계는 사용자의 상태를 이용하여 로직을 처리할때 문제가 발생합니다.
무슨 이야기냐구요…? 🫨
상태를 이용할 때 발생하는 문제
webApplication1을 통해서 서비스를 이용한 사용자가 있었습니다.
이때, 갑자기 webApplication1가 다운되었고,
로드밸런서는 이를 감지하고 webApplication2로 모든 트래픽 처리를 위임했습니다.
여기까지는 문제가 없는 것 같습니다...!
그런데 webApplication1이 사용자의 session을 이용하여
서비스를 제공하고 있었다면 webApplication2는 사용자의 session을 파악하고 처리할 수 있을까요…? 🫨
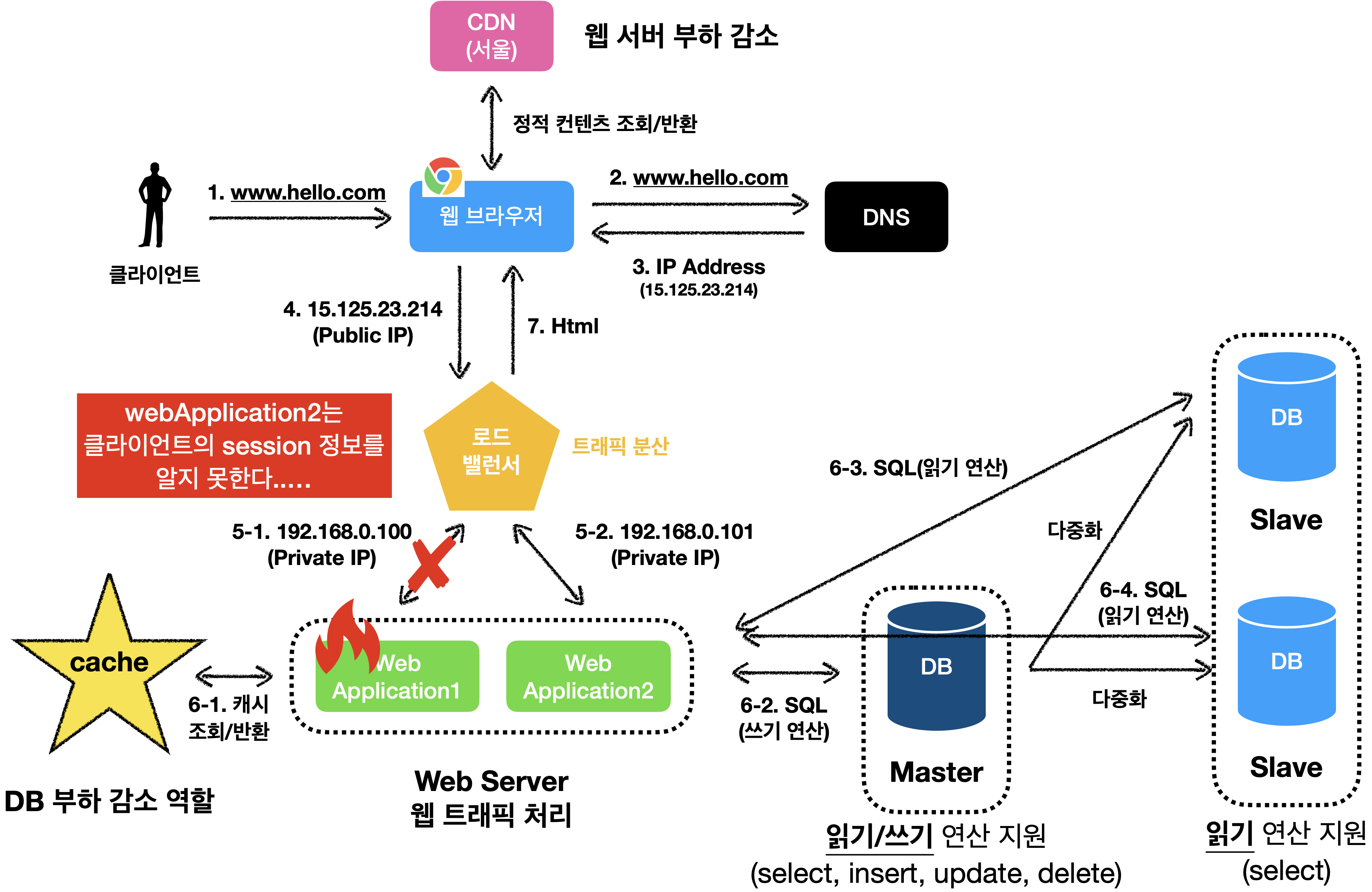
이러한 문제 뿐만 아니라, 서버가 다운되지 않아도 사용자의 상태를 이용하면 로드밸런서는 사용자 상태를 저장하고 있는 webApplication으로만 트래픽을 보내야 합니다…..
같은 클라이언트로 부터 요청은 항상 같은 서버로 전송되어야 하는 것이죠…
다행히도 대부분 로드밸런서가 이를 지원하기 위해 고정 세션(sticky session)이라는 기능을 제공하는데, 이는 로드밸런서에게 부담을 주는 작업 입니다.
우리가 사용하는 웹 계층은 HTTP를 사용합니다.HTTP는 기본적으로 무상태성(statelsess) 프로토콜 입니다.
무상태성이기 때문에 우리는 쉽게 웹 계층을 확장할 수 있습니다.!!
그런데, 상태 정보를 이용하는 지점이 필요합니다. 🥲
참고
무상태 프로토콜은 서버가 클라이언트의 상태를 보존하지 않는 특징을 가지고 있습니다.
상태는 필요한데, 웹계층을 쉽게 확장하기 위해서는 무상태성을 유지해야 한다….
어떻게 해야할까요…? 🤔
정답은 생각보다 간단합니다.
우리는 무상태성(stateless)을 유지하면서 웹 계층을 수평적으로 확장하기 위해서는 상태 정보를 웹 계층에서 제거해야 합니다.
상태 정보를 RDBMS 또는 NoSQL같은 지속성 저장소에 보관하고, 필요할 때 가져오도록 하는 것 입니다!
무상태성을 유지하면서 웹 계층을 확장가능한 설계
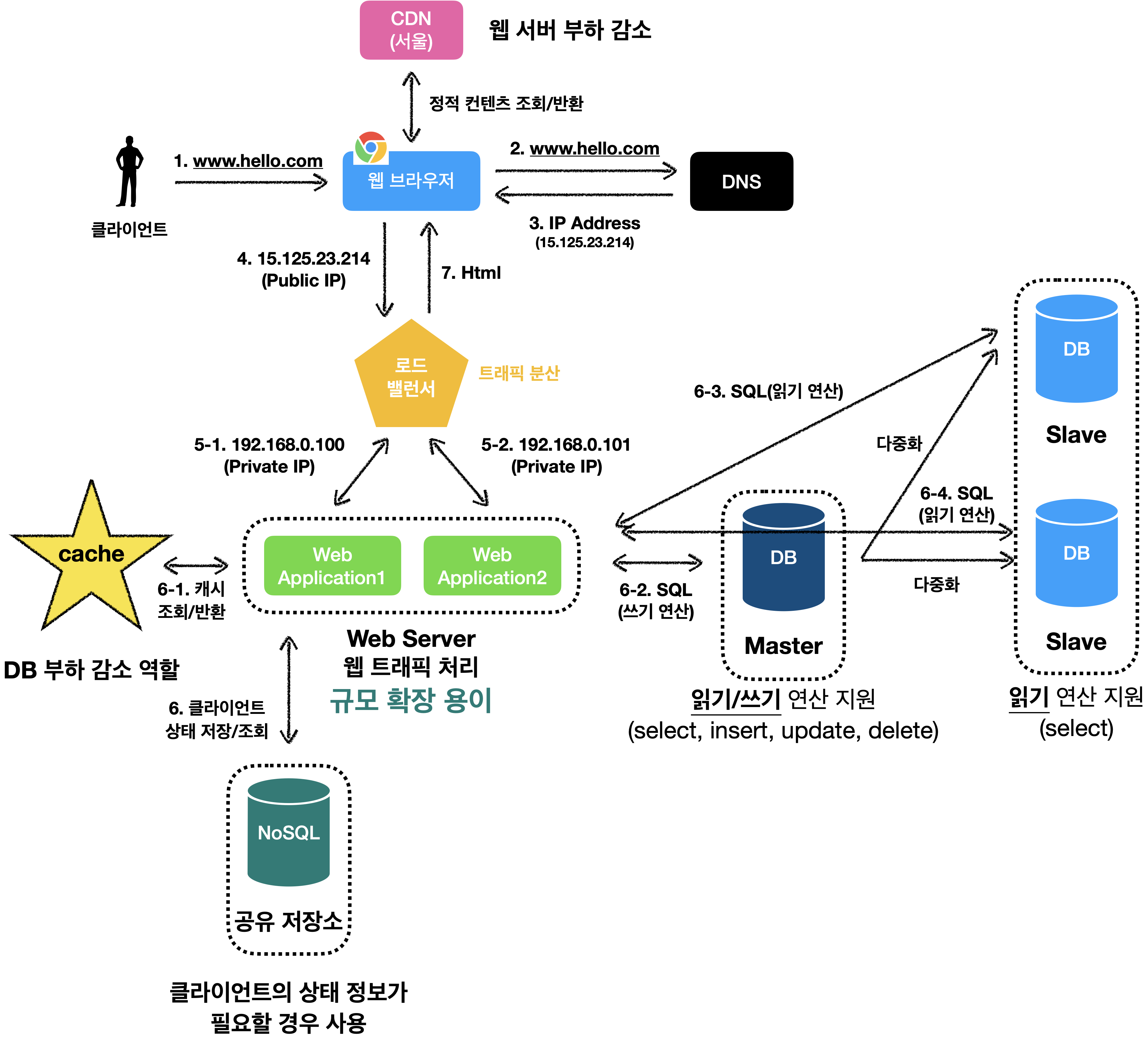

이렇게 하면, 웹 서버로 부터 상태 정보는 물리적으로 분리할 수 있어, 구조적으로 단순하고, 안정적이며, 규모확장이 용이합니다.!
상태 정보가 웹 서버들로 부터 제거되었기 때문에, 트래픽 양에 따라 웹 서버를 수평적으로 넣고, 빼면 됩니다!
참고
공유 저장소는 RDBMS를 사용할 수도 NoSQL을 사용할 수도 있고, Redis같은 캐시 시스템을 사용할 수도 있습니다.
NoSQL을 사용한 이유
규모 확장이 간편하기 때문 입니다!NoSQL 데이터베이스는 고정된 테이블 구조가 필요하지 않습니다.
즉, 데이터베이스 설계를 변경하지 않고도 필요한 새로운 속성을 동적으로 추가할 수 있습니다.
글로벌 서비스에 필요한 것
이제는 여러분의 웹 서비스가 성장에 성장에 성장을 거듭하여,
🌎 전 세계가 당신의 서비스를 이용한다고 가정해 봅시다.
전 세계 이용자들이 편-안하게 이용하기 위해서는 여러 데이터 센터를 지원하는 것이 필수 입니다.!!!
데이터 센터(with geoDNS-routing)
아래는 2개의 데이터센터를 운영하는 설계 입니다.
장애가 없는 상황에서 사용자는 가장 가까운 데이터 센터로 안내되고,
이러한 절차를 지리적 라우팅(geoDNS-routing | geo-routing)이라고 합니다.
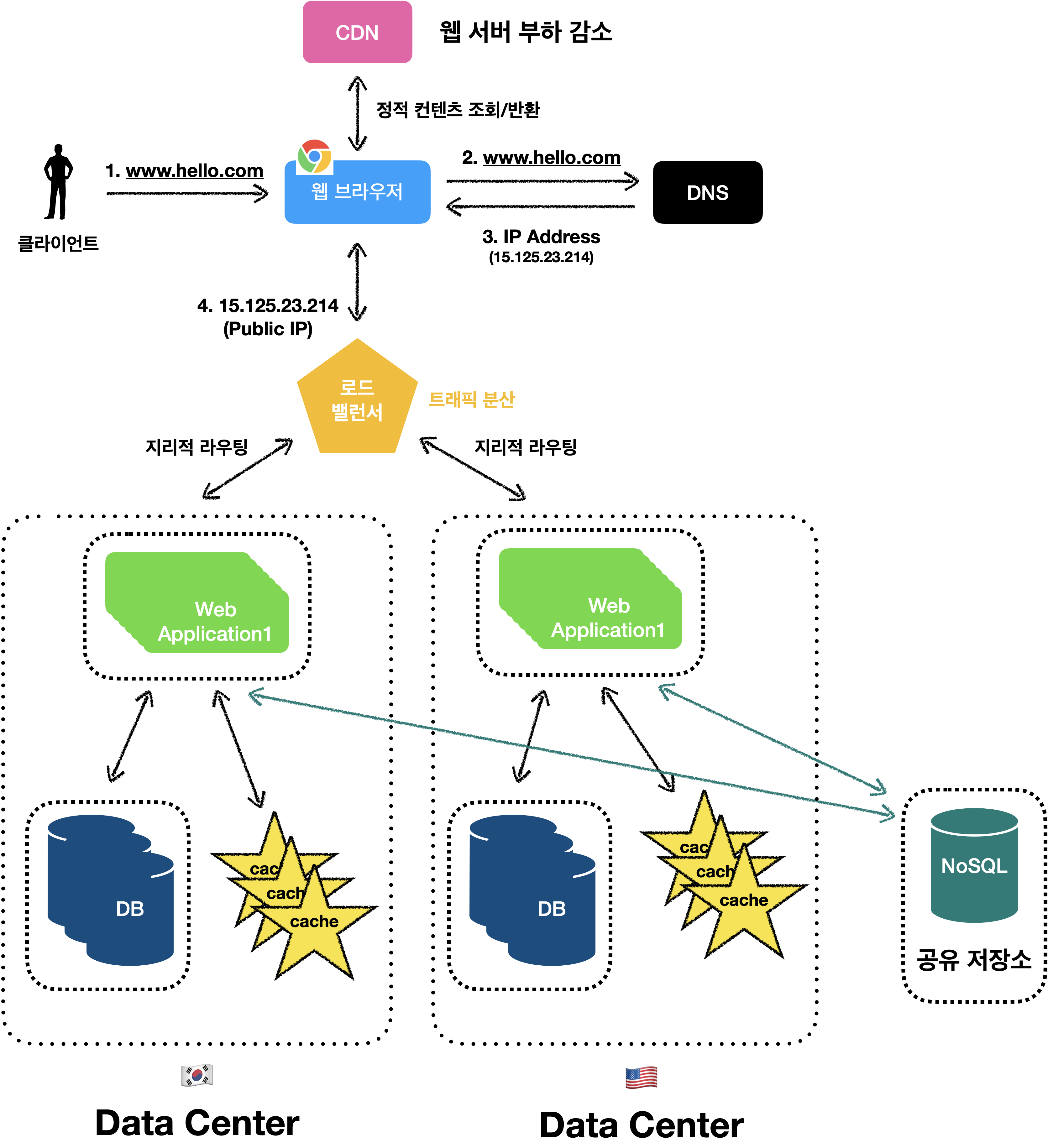

지리적 라우팅에서 GeoDNS는 사용자의 IP 위치에 따라 도메인 이름을 어떤 IP 주소로 변환할지 결정할 수 있도록 해주는 DNS 서비스 입니다.(GeoDNS 덕분에 트래픽 우회 문제를 해결할 수 있습니다.)
하지만, 장애가 발생하면 어떻게 될까요..? 🤔
로드밸런서를 통해서 모든 트래픽을 장애가 발생하지 않은 데이터센터로 전송할 것입니다.
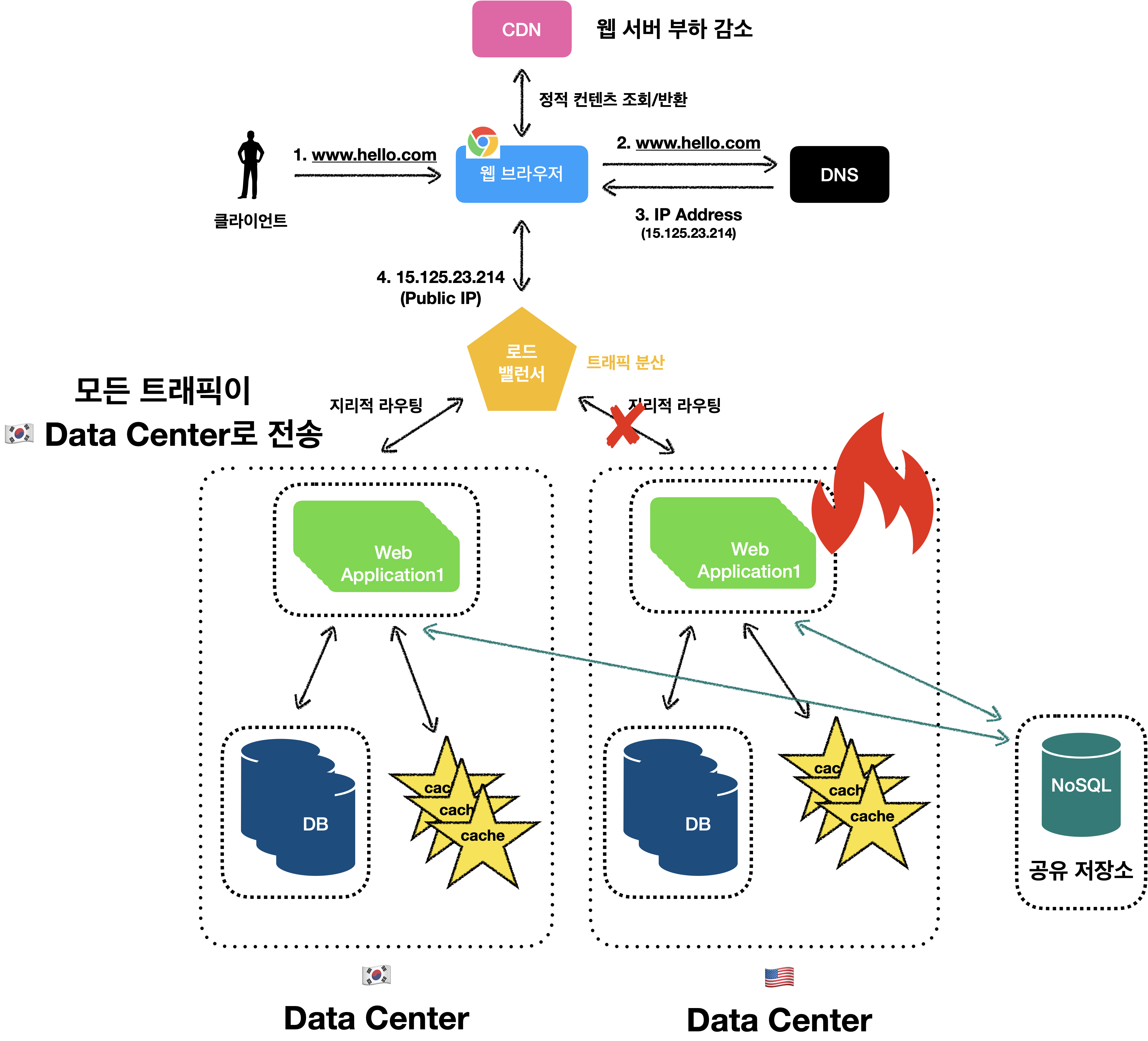

로드밸런서 덕분에 문제가 해결된 것 처럼 보이는데,
다중 데이터센터 아키텍처를 사용하려면 몇 가지 기술적 난제를 해결해야 합니다.
다중 데이터센터 아키텍처의 문제
- 트래픽 우회
- 올바른 데이터 센터로 트래픽을 보내는 효과적인 방법을 찾아야 합니다.
GeoDNS덕분에 사용자에게 가장 가까운 데이터 센터로 트래픽을 보낼 수 있도록 합니다.
- 데이터 동기화(synchronization)
- 데이터 센터마다 별도의 데이터베이스를 사용하기 때문에, 장애가 복구되면, 해당 데이터센터에 데이터가 없을 수 있습니다.(장애가 발생하여 미국사용자가 한국 데이터센터를 이용하다가 장애가 복구되어 다시 미국 데이터센터를 이용하는 상황)
- 이런 상황을 예방하는 보편적인 전략은 데이터를 여러 데이터센터에 걸쳐 다중화하는 것 입니다.
- 테스트와 배포
- 자동화된 배포 도구를 사용하여 웹 사이트 또는 애플리케이션을 여러 데이터 센터에서 테스트해보는 것이 중요합니다.
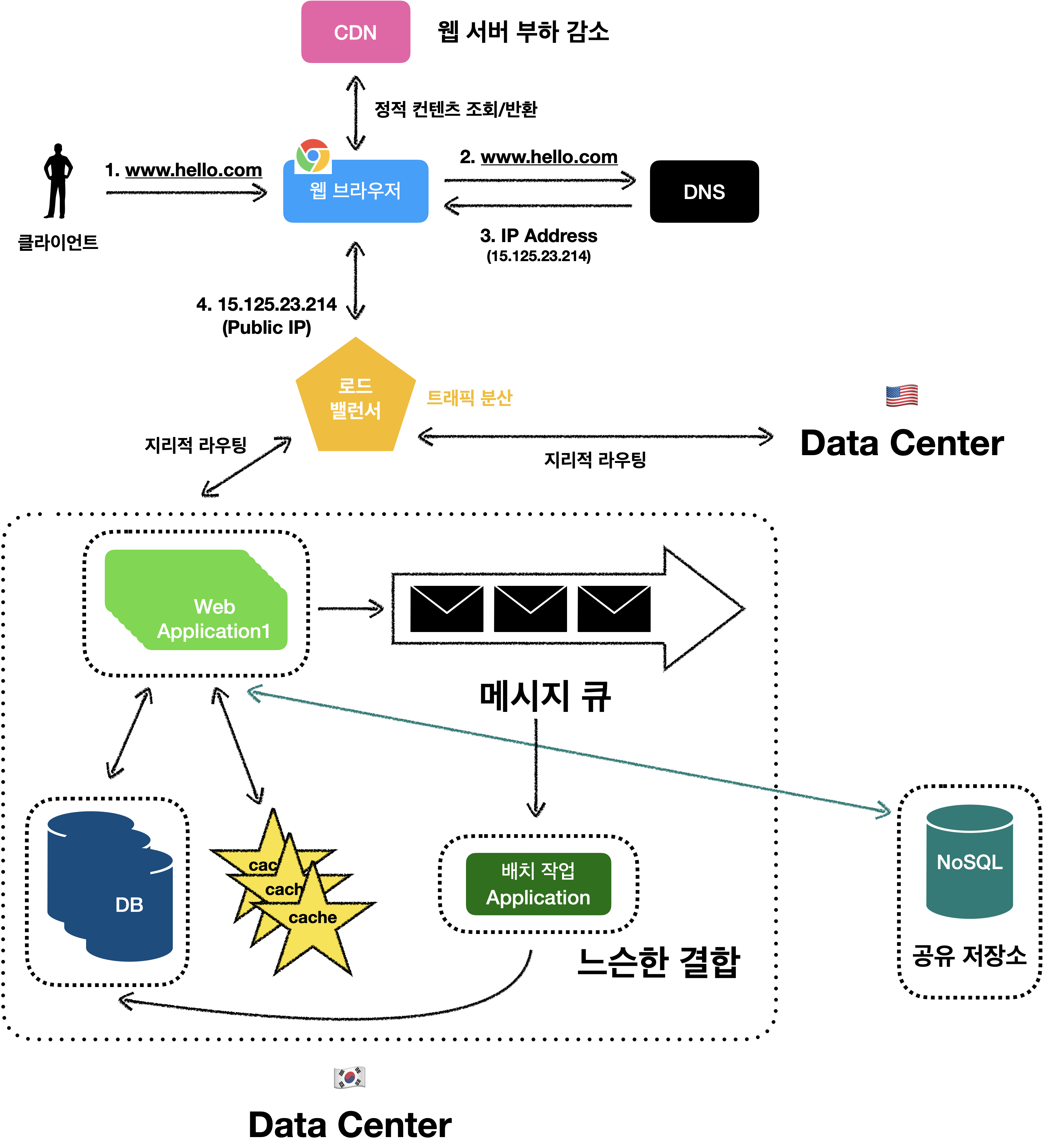
여기에서 시스템을 더 큰 규모로 확장하기 위해서는 시스템의 컴포넌트를 분리하여, 각기 독립적으로 확장될 수 있도록 해야 합니다.
메시지 큐(Message Queue)
메시지 큐는 실제로 많은 분산 시스템이 독립적으로 확장될 수 있도록 해주는 핵심적인 전략 중 하나 입니다.
메시지 큐는 메시지(데이터)의 무손실을 보장하는 비동기 통신을 지원하는 컴포넌트 입니다.(버퍼라고 이해하면 쉽습니다.)
참고
메시지 큐에 보관된 데이터는 소비자가 꺼낼 때까지 안전하게 보관됩니다.
메시지 큐의 구조
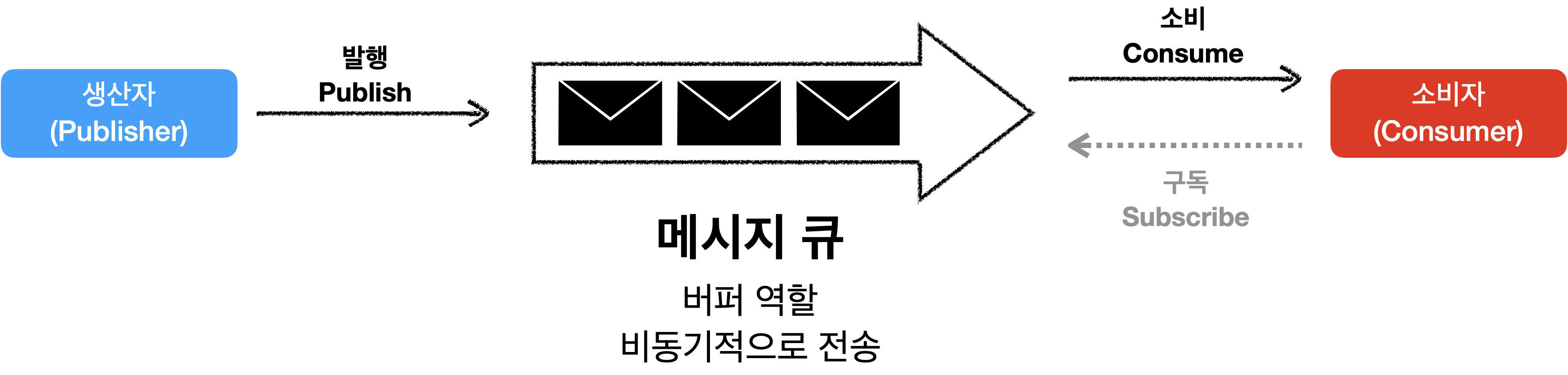

- 생산자가 메시지를 만들어 메시지 큐에 발행(비동기적으로)
- 소비자는 구독을 통해 메시지를 받고 알맞은 동작 수행
메시지 큐를 이용하면 서비스 또는 서버 간 결합이 느슨해져서,
규모 확장성이 보장되어야 하는 안정적 애플리케이션을 구성하기 용이 합니다.^^
생산자는 소비자에 문제가 생겨도 메시지를 발행할 수 있고,
소비자는 생산자에 문제가 생겨도 메시지 큐에 메시지를 수신할 수 있습니다.
메시지 큐 적용

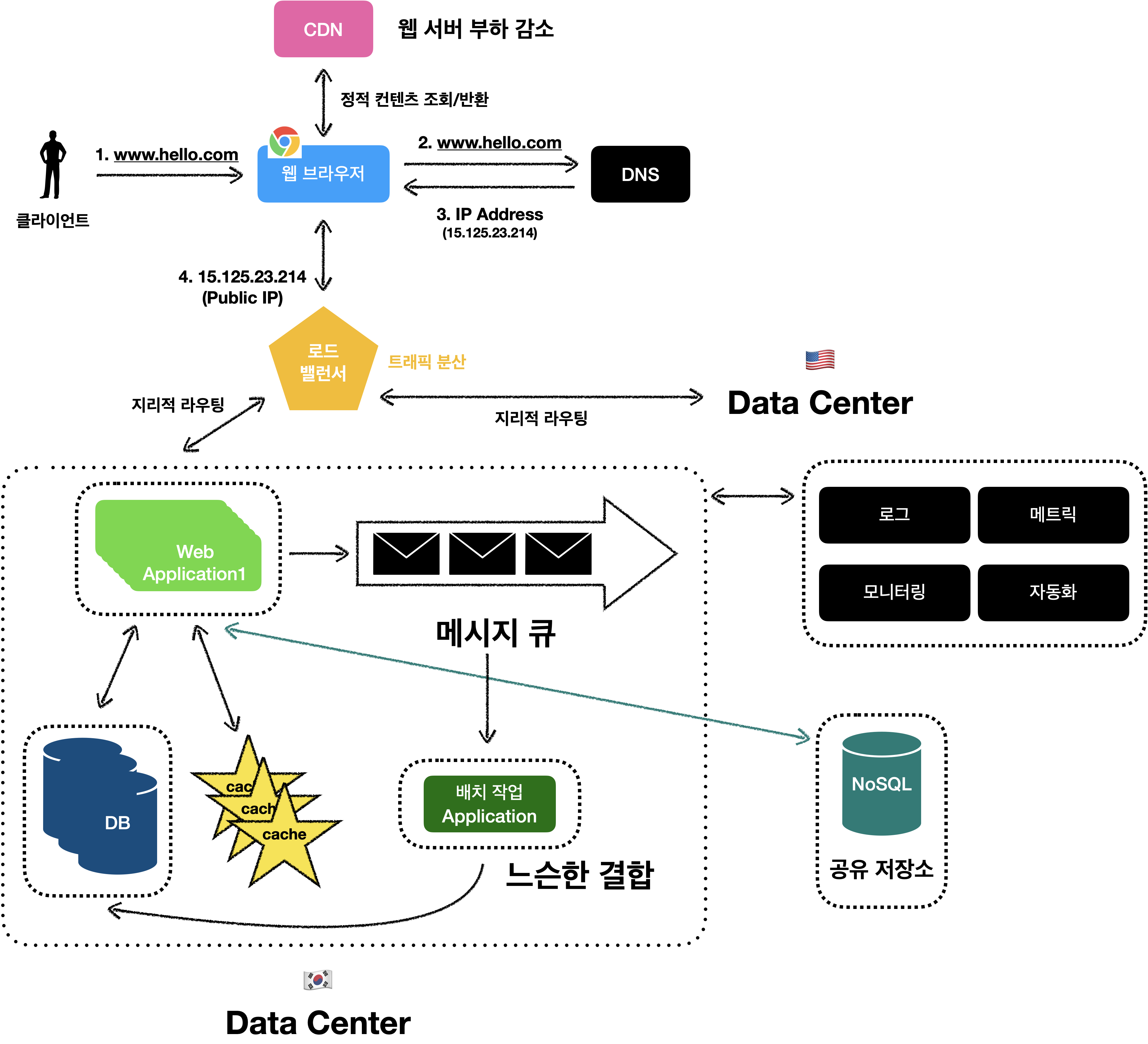
로그, 메트릭 그리고 자동화
몇 개의 서버에서 실행되는 소규모 서비스는 로그나 메트릭, 자동화 같은것을 하면 좋지만, 반드시 할 필요는 없습니다.
하지만, 현재 우리는 글로벌 사용자가 이용하는 대규모 서비스를 운영하고 있습니다.
따라서 우리는 로그, 매트릭, 자동화 같은 도구 사용을 필수적으로 고려해야 합니다.
로그
에러 로그를 모니터링 하는 것은 매우 중요합니다.
시스템의 오류와 문제들을 쉽게 찾을 수 있기 때문입니다.
로그는 서버 단위로 모니터링 하면 좋지만, 우리는 지금 여러 서버를 관리하고 있는 상황이니 여러 서버에서 발생한 로그를 단일 서버로 모아주는 도구를 활용하면 편리하게 모니터링하고 추적할 수 있습니다.
메트릭
보편적으로 메트릭(metric)이란 우리가 대시보드를 볼때 특정 수치들을 그래프로 보여주는 일종의 시각화라고 이해하면 됩니다.
- 호스트 단위 메트릭
- CPU, 메모리, 디스크 I/O에 관한 메트릭
- 종합 메트릭
- 데이터베이스 계층의 성능, 캐시 계층의 성능
- 핵심 비즈니스 메트릭
- 일별 사용자, 재방문, 수익
자동화
시스템이 크고 복잡해지면 많은 개발자들이 하나의 서비스를 개발하게 됩니다.
그러면 생산성을 높이기 위해서 자동화 도구를 잘 활용해야합니다.
예로 지속적 통합(continuous integration: CI)을 도와주는 도구를 활용하면 개발자가 작성한 코드가 어떤 검증 절차를 자동으로 거치도록 할 수 있어, 문제를 쉽고 빠르게 발견할 수 있습니다.
로그, 메트릭, 자동화를 반영한 설계

데이터베이스의 규모 확장
앞에서 우리는 데이터베이스를 분리하고, 장애에 대응하기 위해 다중화(master <—> slave)를 했습니다.
그런데 다중화를 했다고 해서 저장할 데이터가 많아지는 것에 대한 부하를 줄이는데는 한계가 있습니다.
결국 데이터베이스를 확장(증설)해야 하는데, 데이터베이스를 확장하기 위해서는 어떤 방법을 사용해야할까요?
데이터베이스를 확장하는 방법은 크게 2가지가 존재합니다.
- 수직적 규모 확장(
scale up) - 수평적 규모 확장(
scale out)
수직적 규모 확장
수직적 규모 확장은 기존 서버에 더 많은, 또는 고성능의 자원을 추가하는 방법 입니다.
이 방법은 매우 단순하게 확장할 수 있다는 장점이 존재하지만, 심각한 단점이 존재합니다.
- 고성능 자원(하드웨어)을 무한하게 증설할 수 없음
SPOF(Single Point of Fail)로 인한 위험성이 큼- 비용 증가
- 고성능 서버 1대가 일반 성능의 서버2대보다 비용이 크다.
수평적 규모 확장(샤딩)
데이터베이스의 수평적 확장은 샤딩(sharding)이라고 부릅니다.
더 많은 서버를 추가함으로써 성능을 향상시키는 방법 입니다.
샤딩은 대규모 데이터베이스를 샤드(shard)라고 부르는 작은 단위로 분할하는 기술을 의미 합니다.
모든 샤드는 같은 스키마를 사용하지만 샤드에 보관되는 데이터 사이에는 중복이 없습니다.
샤드로 분할된 데이터베이스
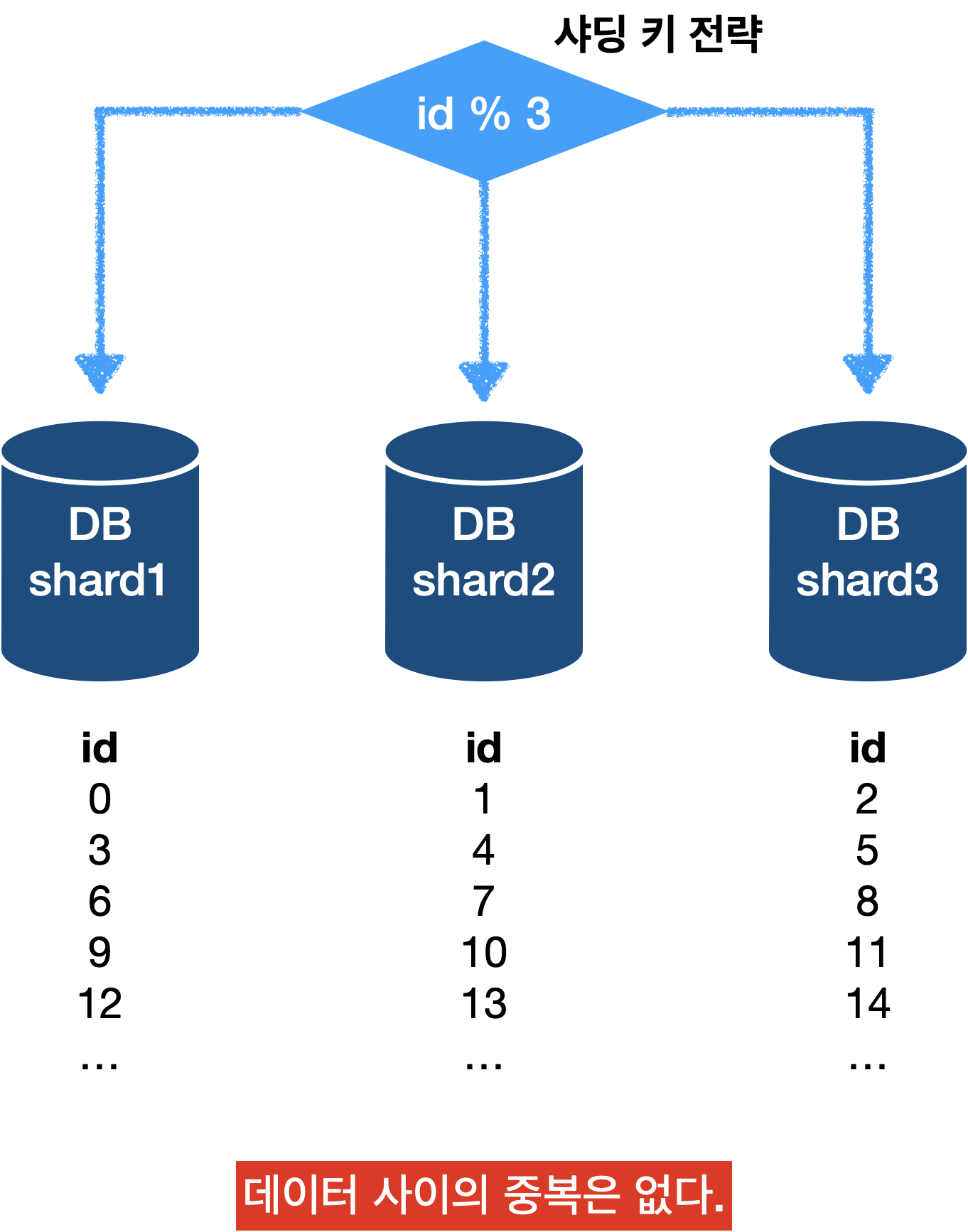

샤딩 전략을 구현할 때 고려해야 할 가장 중요한 것은 어떤 것을 샤딩 키(sharding key)로 사용하는가? 입니다.
샤딩 키를 정할 때는 데이터를 고르게 분산할 수 있는 것이 가장 중요하기 때문에 이를 명심하고 선택하면 좋을 것 입니다.
샤딩은 데이터베이스 규모를 확장하는데 훌륭한 기술이지만, 모든 기술이 그렇듯 완벽하진 않습니다.
샤딩 도입시 고려사항
- 데이터의 재 샤딩
- (1) 데이터가 너무 많아서 현재 샤드들로는 감당하기 어려울 때
- (2) 샤드 간 데이터 분포가 균등하지 못하여 어떤 샤드에 할당된 공간 소모가 다른 샤드에 비해 빨리 진행될 때
- (1), (2)의 경우처럼 샤드 소진(
shard exhaustion)이라고 불리는 현상이 발생하면, 샤드 키를 계산하는 함수를 변경하고 데이터를 재배치해야 합니다.(안정 해시 기법을 통해 해결할 수 있습니다.)
- 유명인사 문제
- 핫스팟(
hotspot key)문제라고 불리며, 특정 샤드에 질의가 집중되어 서버에 과부하가 걸리는 문제 입니다. BTS,봉준호,손흥민과 같은 월드클래스(유명인사)가 전부 같은 샤드에 저장되어 있다고 해보자. 이 데이터를 기반으로 애플리케이션을 구축하면 결국 해당 샤드에는 과부하가 걸리게 될 것 입니다.- 유명인사 문제를 해결하기 위해서는 유명인사를 각각 서로 다른 샤드에 배치하거나, 심지어 더 잘게 쪼개야할 수도 있습니다.
- 핫스팟(
- 조인과 비정규화
- 하나의 데이터베이스를 여러 샤드 서버로 분리하고 나면, 당연하게도 데이터를 조인하기 어려워 집니다.
- 이를 해결하는 1가지 방법은 바로 데이터베이스를 비정규화하여 하나의 테이블에서 질의가 수행될 수 있도록 하는 것 입니다.
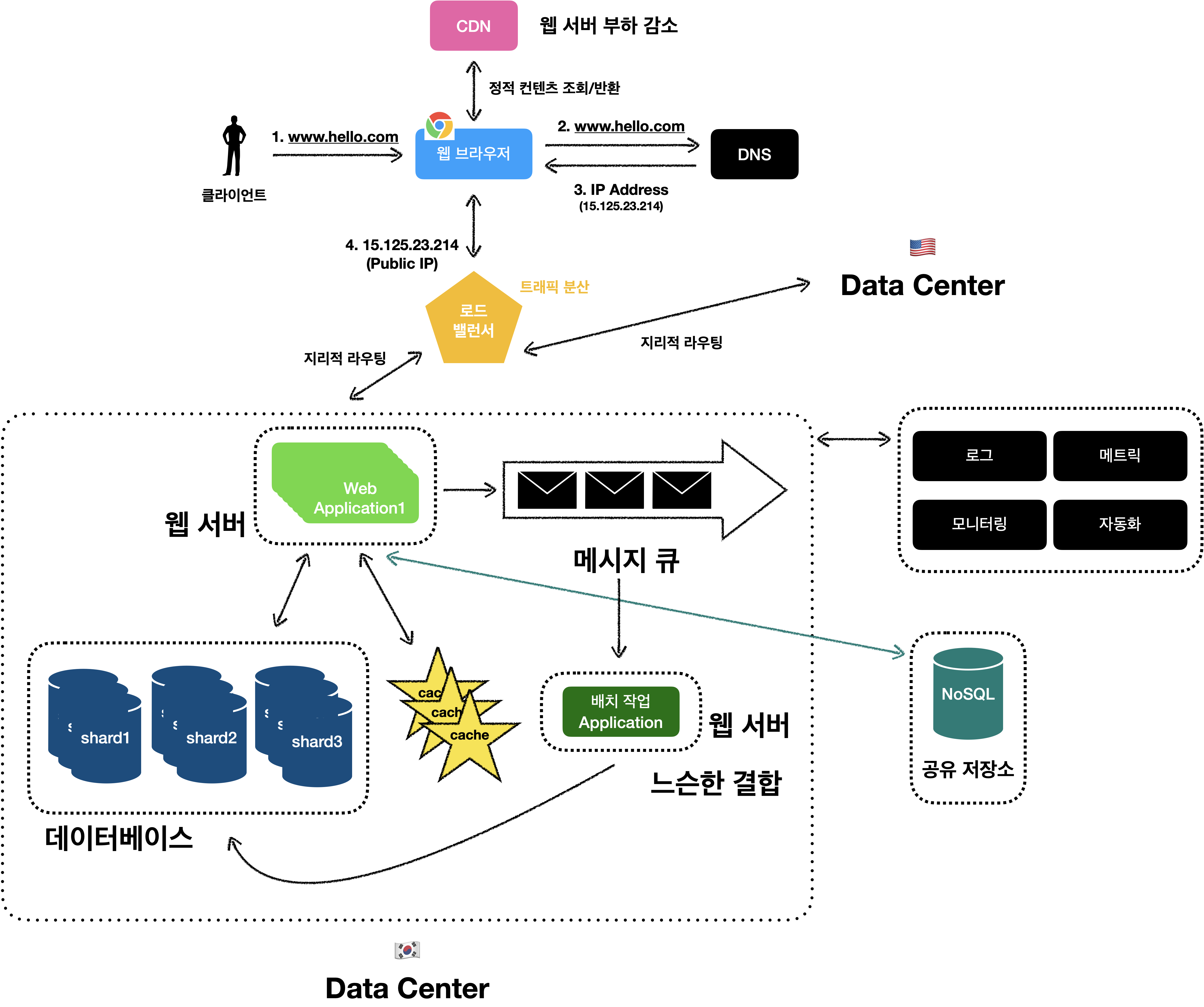

정리
여기까지 읽으시느라고… 정말로 수고하셨습니다.!
지금까지 단일 서버 구조를 글로벌 서비스가 가능한 설계로 확장하면서 적용한 개념들을 정리해보겠습니다.
- 웹 계층과 데이터 계층 분리
- 모든 계층에 다중화 도입
- 가능한 많은 데이터 캐시
- 정적 컨텐츠는
CDN을 통해서 서비스 - 웹 계층은 무상태 계층으로 설계
- 여러 데이터 센터 지원
- 메시지 큐를 이용한 웹 계층 확장 용이성 확보
- 데이터 계층은 샤딩을 통해 규모 확장
- 시스템을 지속적으로 모니터링하기 위한 자동화 도구 활용
참고
'0 + 독서 > 가상 면접 사례로 배우는 대규모 설계 기초' 카테고리의 다른 글
| [가상 면접 사례로 배우는 대규모 설계 기초] 2. 처리율 제한 장치(Rate Limiter) (2) | 2023.10.09 |
|---|